
AWS
AWS Glue + Athena로 CSV 불러오기
1. 개요
이전 글에서는 Azure Databricks를 이용해서 타이타닉 데이터를 PySpark로 분석을 했었습니다
이번엔 AWS에서도 유사한 흐름으로 분석을 진행해 볼까 합니다
이번 편에서는 단순 CSV 불러오기 까지 진행하고
다음 편부터 본격적인 분석을 진행해보겠습니다.
2. 구성 요소
S3 : 타이타닉 CSV 데이터를 저장하는 스토리지
AWS Glue Crawler : S3에 저장된 다양한 형식의 데이터를 스캔하고 이 데이터의 스키마를 자동으로 추론해서 테이블 형태로 등록해 주는 친구입니다.
Azure에는 Azure Data Factory + Data Catalog에 대응되고
AWS Athena : S3에 저장된 데이터에 대해서 표준 SQL로 쿼리를 날릴 수 있는 서비스입니다.
Azure SQL에 대응되는 것 같습니다 (1대1 대응은 아님)
3. 진행 과정:
S3 버킷 생성 및 업로드
Amazon S3 콘솔에서 cjwoobucket이라는 이름의 버킷을 생성합니다. 이후 Titanic 데이터를 담고 있는 CSV 파일을 이 버킷에 업로드할 예정입니다. S3는 위에 언급했듯이 분석 대상 데이터를 저장하는 스토리지 역할을 하며, 이후 Glue Crawler와 Athena에서 참조하게 됩니다.

업로드를 클릭하여 타이타닉 CSV 데이터셋을 업로드해줍니다.
Glue Crawlers 설정
Create crawler를 클릭해 줍니다.

Step1은 간단히 이름만 적고 넘어가고
Step 2에서는 아직 등록된 데이터 소스가 없으니 직접 S3를 지정해줘야 합니다.
참고로 여기서 말하는 Glue 테이블로 매핑된 데이터냐?라는 말은 Athena에서 이미 쿼리 해본 데이터냐는 뜻인데 처음부터 등록하는 거라 Not yet을 선택해 줍니다

데이터 소스로 사용할 S3 경로를 지정해 줍니다.저는 cjwoobucket 버킷 아래 titanic/ 폴더에 데이터를 넣었습니다
무조건 버킷 아래 폴더가 있어야 경로가 인식됩니다.
Subsequent crawler runs는 이후 크롤링 시 어떤 범위까지 다시 읽을지를 설정하는 옵션인데,
그냥 기본값인 Crawl all sub-folders로 두고 넘어가줍니다

IAM 역할이 아직 없다면, [Create new IAM role] 버튼을 눌러 새로 만들어줍니다.
IAM 역할 이름은 기본 제안 형식인 AWSGlueServiceRole-xxxx 형식으로 입력하면 되고
저는 AWSGlueServiceRole-cjwoocrawler로 설정했습니다.
뒤에 이름은 중요하지 않지만 AWSGlueServiceRole-이 붙어야 Glue에서 인식한다고 합니다

데이터를 크롤링한 결과를 저장할 대상 데이터베이스를 설정합니다.
이미 만들어둔 DB가 있다면 드롭다운에서 선택하면 되고, 없다면 [Add database] 버튼 눌러 새로 만들어줍니다

새 DB를 생성할 때는 이름만 입력하면 됩니다
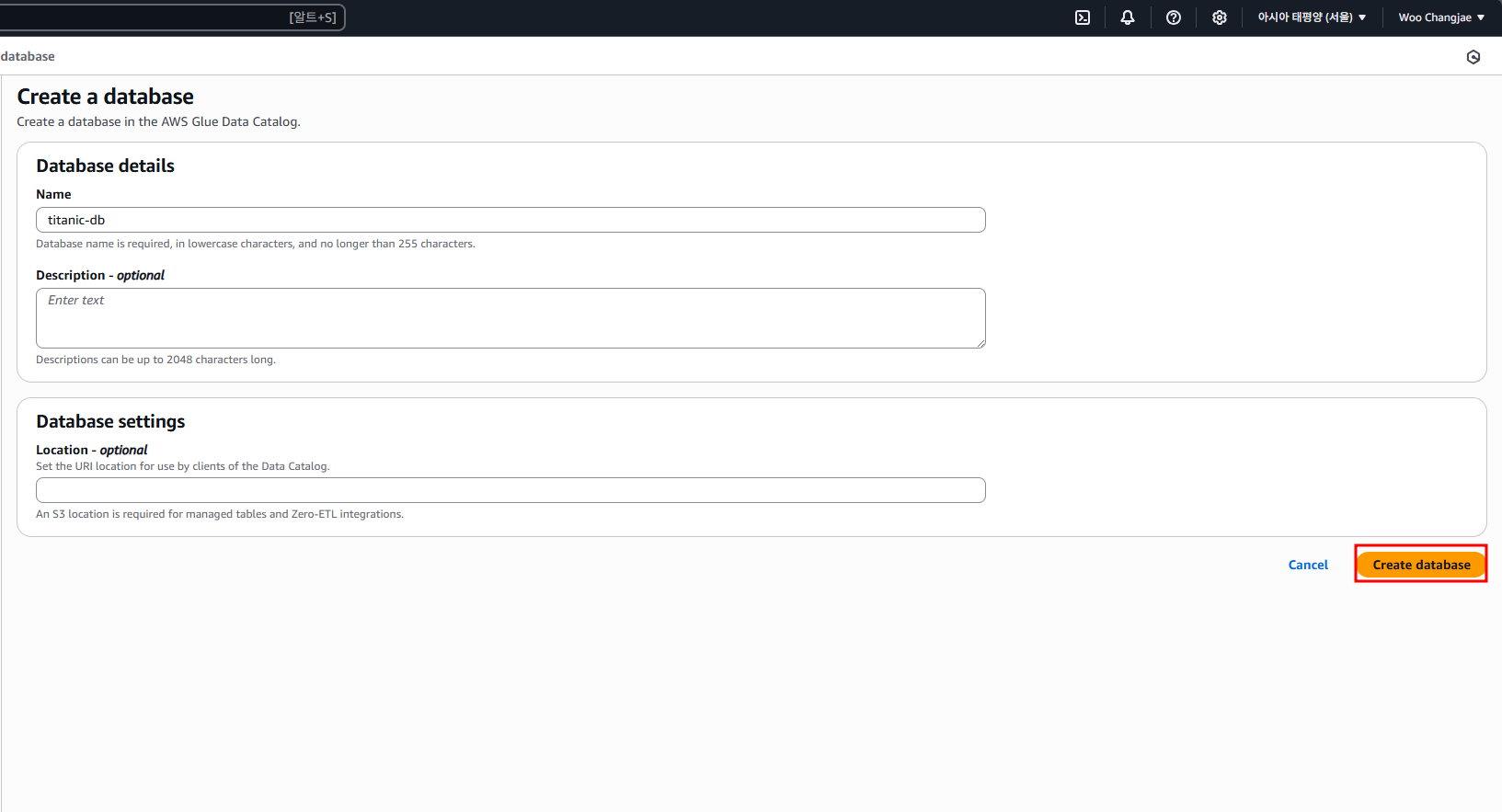
다시 돌아와서 방금 만든 titanic-db를 선택해 주면 되고
Crawler가 이 DB 안에 테이블들을 자동으로 생성해 줍니다 실행 주기는 필요할 때만 수동 실행하는 On demand로 둡니다

최종적으로 검토해 본 뒤 생성해 줍니다.
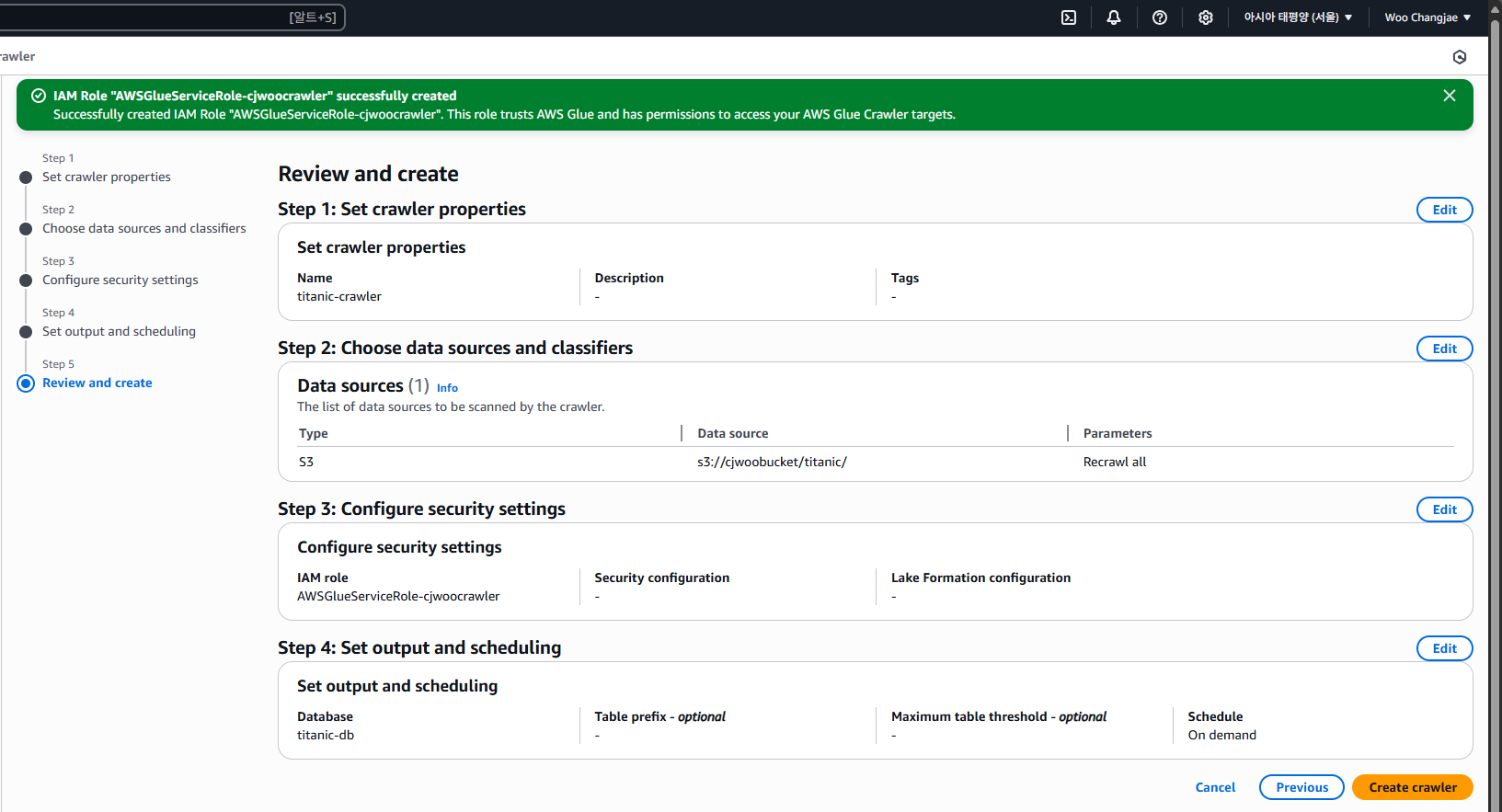
Glue Crawlers 실행 및 테이블 생성
이제 데이터를 긁어오기 위해 Run Crawler 버튼을 눌러 실행해 줍니다
누르면 자동으로 S3 경로에 있는 데이터를 읽어서 Glue Data Catalog에 테이블 스키마를 만들어줍니다


Amazon Athena 생성 및 실행
Crawler 실행이 끝났으면 이제 Athena로 넘어갑니다 [S3 + Glue + Athena] 조합의 마지막 단계입니다.

이제 본격적으로 Athena에서 쿼리를 날려보겠습니다
좌측에서 데이터 원본은 기본으로 있는 AwsDataCatalog,
데이터베이스는 우리가 Glue에서 지정해 뒀던 titanic-db를 선택해 주면 됩니다.
테이블도 자동으로 잘 생성돼 있고 titanic 테이블 클릭해서 스키마 확인한 뒤,
SELECT * FROM "titanic-db"."titanic" LIMIT 10;위와 같이 쿼리를 실행하니 잘 뜨는 것을 볼 수 있었습니다.
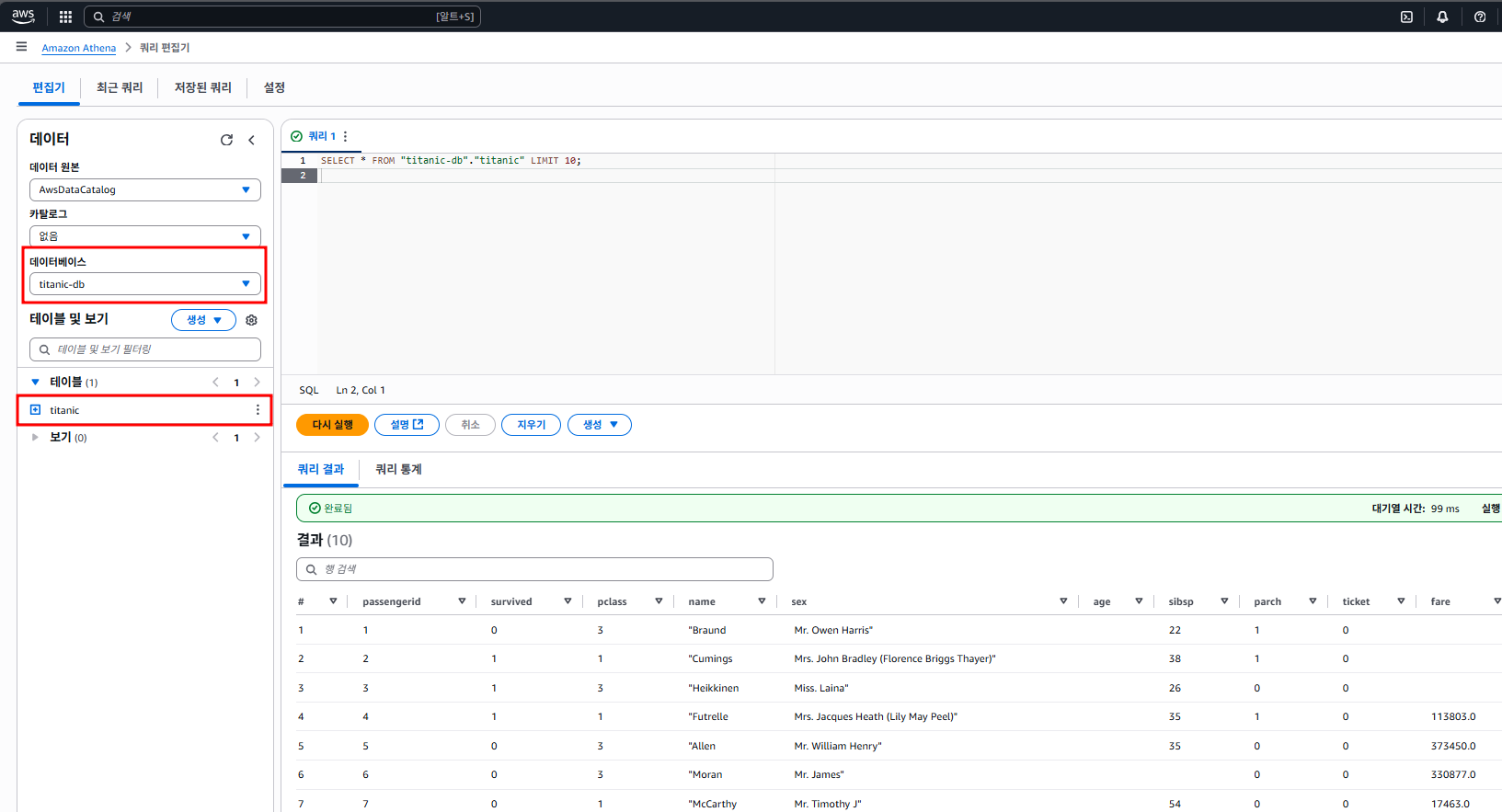
이제부터는 S3에 있는 CSV 데이터를 자유롭게 SQL로 분석할 수 있습니다.
AWS 첫 포스팅입니다.
다음 편에서는 Azure Databricks와 대응되는 AWS로 포스팅하겠습니다.
<참고자료>
크롤러를 사용하여 데이터 카탈로그 채우기 - AWS Glue
크롤러를 사용하여 데이터 카탈로그 채우기 - AWS Glue
크롤러를 사용하여 데이터 카탈로그 채우기 AWS Glue 크롤러를 사용하면 데이터베이스 및 테이블을 사용하여 AWS Glue Data Catalog를 채울 수 있습니다. 대부분의 AWS Glue 사용자가 사용하는 기본적인
docs.aws.amazon.com