
AWS
AWS Glue Job + PySpark로 타이타닉 데이터 분석하기
1. 개요
이번에는 AWS Glue의 PySpark 기반 Job을 활용해 Titanic 데이터를 분석하고,
그 결과를 S3에 저장한 뒤 Athena를 통해 SQL로 다시 조회해 보도록 하겠습니다
Azure Databricks에서도 유사한 PySpark 분석 실습을 진행했지만,
Glue만으로 동일한 분석 파이프라인을 구현해보았습니다.
S3에 저장된 CSV 파일을 Glue Crawler로 테이블화하고,
Glue Job에서 PySpark로 데이터를 전처리 및 집계한 후,
결과를 다시 S3에 저장하여 Athena에서 쿼리해보도록 하겠습니다
2. 구성 요소
Amazon S3 : Titanic CSV 파일 및 분석 결과 저장소로 사용
AWS Glue Crawler : S3에 업로드된 CSV 파일의 구조를 자동 인식해서 Glue Data Catalog에 테이블로 등록
AWS Glue Job : PySpark 코드 기반으로 데이터를 전처리하고, 컬럼을 만들고, 집계 연산을 수행. 분석 결과는 다시 S3에 저장
Amazon Athena : Glue Job이 생성한 분석 결과를 SQL로 쿼리하여 확인
3. 진행 과정
전체적인 진행 과정은 다음과 같습니다.
Titanic 데이터 S3 업로드 → Glue Crawler로 테이블 생성 → Glue Job 생성 → 분석 결과 S3에 저장 → Athena에서 결과 테이블 생성 및 조회

Titanic 데이터 S3 업로드
이 부분은 저번 포스팅 때 다뤘으므로 빠르게 넘어가겠습니다.


Glue Crawler로 테이블 생성
먼저 Glue Crawler의 이름을 지정합니다. 저는 titanic-crawler라는 이름으로 설정...했고
이 이름은 Data Catalog에 등록될 테이블과 관련된 작업 흐름을 구분하는 데 사용되다 보니
CSV 파일의 주제를 드러낼 수 있도록 직관적으로 정해주는 것이 좋습니다


DB도 S3 내의 데이터 기반으로 만들어줍니다


이제 저번과 마찬가지로 Run crawler를 눌러줍니다


Crawler 실행이 완료되면 Glue의 Data Catalog → Tables메뉴에서 자동으로 생성된 테이블을 확인할 수 있습니다.
cjwoo_titanic이라는 이름의 테이블이 생성되었고, 연결된 데이터베이스는 titanic-db입니다.
테이블을 클릭하면 상세 페이지에서 S3 경로, 파일 포맷, 그리고 스키마 정보를 확인할 수 있습니다.
아래와 같이 Titanic 데이터셋의 컬럼들이 자동으로 인식되어 등록된 것을 확인할 수 있습니다.

Glue Job 생성 및 스크립
이제 ETL 작업을 진행하기 위해 AWS Glue Studio → ETL jobs 메뉴로 이동합니다.
Glue Studio에서는 파이프라인을 구성할 수 있는데요
Create job from a blank graph 버튼을 살포시 클릭하여 새로운 작업을 생성합니다.

작업 생성 이후 상단의 스크립트 탭을 보면 AWS Glue에서 자동 생성한 PySpark 코드가 표시되어 있습니다

아까 생성한 Glue Data Catalog의 테이블을 PySpark의 DynamicFrame으로 불러온 뒤, 일반 Spark DataFrame으로 변환합니다
이후, 나이(age) 컬럼의 null 값을 0으로 채우고 age_group이라는 새 컬럼을 생성하여 연령대에 따라 탑승자를 분류합니다.
타이타닉 같은 유명한 데이터셋에 왜 null 칼럼이 있나 했더니 이러한 작업을 위해 일부로 만들었다고 합니다;; 당황스럽네요

Job 이름은 그럴듯하게 설정하고 IAM Role은 AWSGlueServiceRole-cjwoo
Job Type은 당연히 Spark입니다 Glue Job은 기본적으로 Spark 환경에서 동작합니다.
그 외 다른 설정은 기본으로 두면 됩니다.

스크립트와 설정이 완료되면 실행해 줍니다 약 260원이 슈루룩 빠져나갑니다.



Glue Job이 정상적으로 실행되었다면, 지정한 S3 경로에 결과 파일이 생성됩니다.
cjwoo-titanic/output/ 경로에 .csv 확장자의 결과 파일이 출력된 것을 확인할 수 있습니다

Athena에서 테이블 생성 및 조회
Glue 작업을 통해 전처리된 결과는 s3://cjwoo-titanic/output/ 경로에 CSV 형식으로 저장됩니다
쿼리 성공 메시지를 통해 테이블이 정상적으로 연결되었음을 확인했고
이후 Amazon Athena에서 해당 경로를 외부 테이블로 등록하여, SQL 기반의 후속 분석이 가능해졌습니다


테이블 생성 후, 성별과 연령대를 기준으로 생존율 평균을 집계하는 쿼리를 간단하게 한번 실행해 봤습니다.

Azure에서는 Databricks에서 PySpark를 통해 데이터를 처리하고 시각화까지 이어갔다면,
AWS에서는 Athena + S3 조합만으로도 SQL 기반의 집계 분석 작업을 간단히 수행할 수 있었습니다.
Athena는 Spark처럼 복잡한 클러스터 구성 없이도, S3에 저장된 파일을 바로 테이블로 인식해 쿼리를 날릴 수 있다는 점이 있고
반면, Databricks는 ML/AI 모델 학습이나 복잡한 파이프라인 구성에 최적화된 플랫폼인 듯합니다
두 클라우드를 비교하는 것도 쏠쏠하게 재밌네요
Amazon Athena란 무엇인가요? - Amazon Athena
Amazon Athena란 무엇인가요? - Amazon Athena
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사합니다. 실망시켜 드려 죄송합니다. 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
'AWS > AWS Database Servises' 카테고리의 다른 글
| AWS Glue + Athena로 CSV 불러오기 (2) | 2025.07.11 |
|---|
AWS Glue + Athena로 CSV 불러오기
1. 개요
이전 글에서는 Azure Databricks를 이용해서 타이타닉 데이터를 PySpark로 분석을 했었습니다
이번엔 AWS에서도 유사한 흐름으로 분석을 진행해 볼까 합니다
이번 편에서는 단순 CSV 불러오기 까지 진행하고
다음 편부터 본격적인 분석을 진행해보겠습니다.
2. 구성 요소
S3 : 타이타닉 CSV 데이터를 저장하는 스토리지
AWS Glue Crawler : S3에 저장된 다양한 형식의 데이터를 스캔하고 이 데이터의 스키마를 자동으로 추론해서 테이블 형태로 등록해 주는 친구입니다.
Azure에는 Azure Data Factory + Data Catalog에 대응되고
AWS Athena : S3에 저장된 데이터에 대해서 표준 SQL로 쿼리를 날릴 수 있는 서비스입니다.
Azure SQL에 대응되는 것 같습니다 (1대1 대응은 아님)
3. 진행 과정:
S3 버킷 생성 및 업로드
Amazon S3 콘솔에서 cjwoobucket이라는 이름의 버킷을 생성합니다. 이후 Titanic 데이터를 담고 있는 CSV 파일을 이 버킷에 업로드할 예정입니다. S3는 위에 언급했듯이 분석 대상 데이터를 저장하는 스토리지 역할을 하며, 이후 Glue Crawler와 Athena에서 참조하게 됩니다.


업로드를 클릭하여 타이타닉 CSV 데이터셋을 업로드해줍니다.

Glue Crawlers 설정
Create crawler를 클릭해 줍니다.

Step1은 간단히 이름만 적고 넘어가고
Step 2에서는 아직 등록된 데이터 소스가 없으니 직접 S3를 지정해줘야 합니다.
참고로 여기서 말하는 Glue 테이블로 매핑된 데이터냐?라는 말은 Athena에서 이미 쿼리 해본 데이터냐는 뜻인데 처음부터 등록하는 거라 Not yet을 선택해 줍니다

데이터 소스로 사용할 S3 경로를 지정해 줍니다.저는 cjwoobucket 버킷 아래 titanic/ 폴더에 데이터를 넣었습니다
무조건 버킷 아래 폴더가 있어야 경로가 인식됩니다.
Subsequent crawler runs는 이후 크롤링 시 어떤 범위까지 다시 읽을지를 설정하는 옵션인데,
그냥 기본값인 Crawl all sub-folders로 두고 넘어가줍니다

IAM 역할이 아직 없다면, [Create new IAM role] 버튼을 눌러 새로 만들어줍니다.
IAM 역할 이름은 기본 제안 형식인 AWSGlueServiceRole-xxxx 형식으로 입력하면 되고
저는 AWSGlueServiceRole-cjwoocrawler로 설정했습니다.
뒤에 이름은 중요하지 않지만 AWSGlueServiceRole-이 붙어야 Glue에서 인식한다고 합니다

데이터를 크롤링한 결과를 저장할 대상 데이터베이스를 설정합니다.
이미 만들어둔 DB가 있다면 드롭다운에서 선택하면 되고, 없다면 [Add database] 버튼 눌러 새로 만들어줍니다

새 DB를 생성할 때는 이름만 입력하면 됩니다
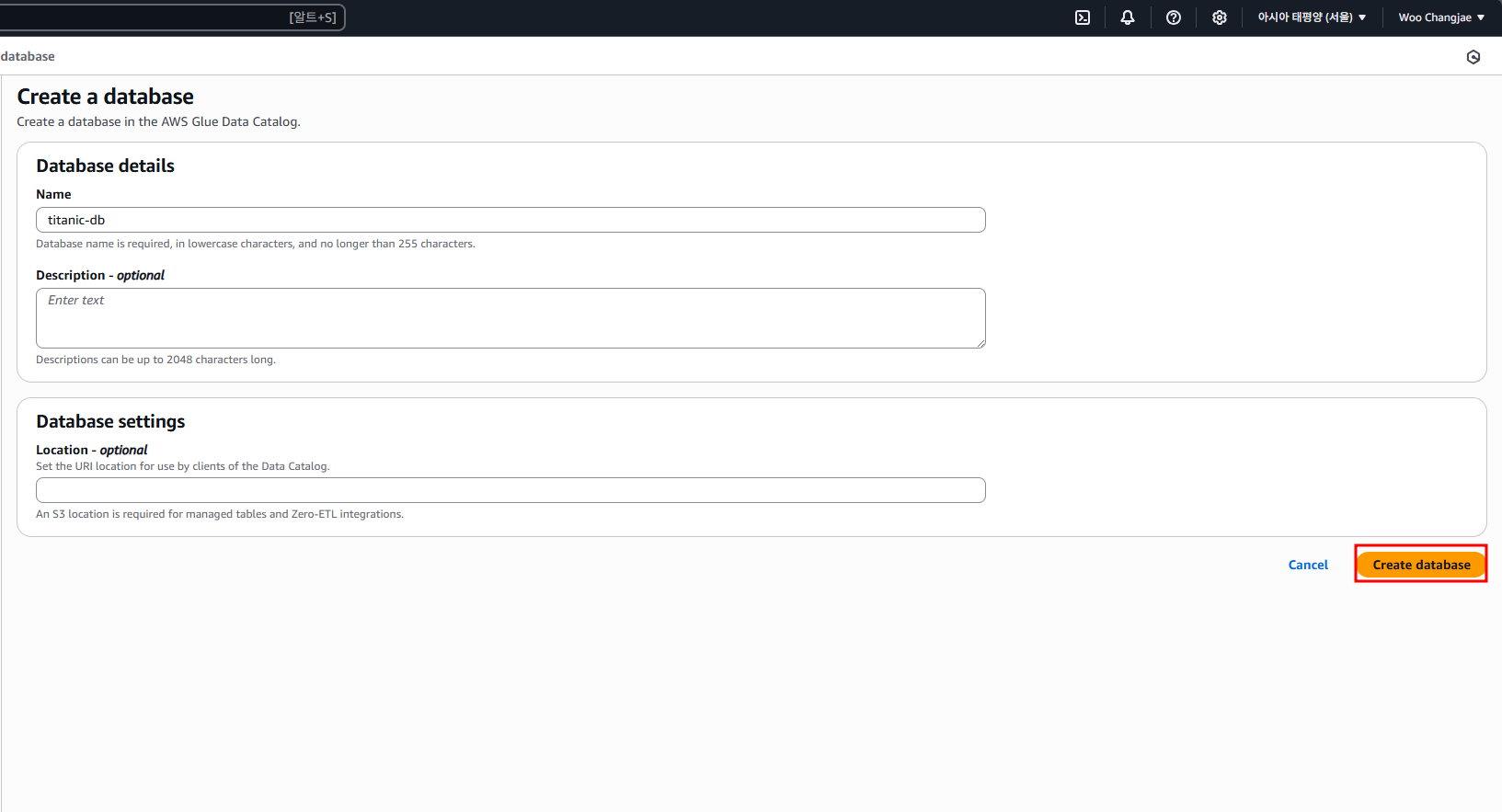
다시 돌아와서 방금 만든 titanic-db를 선택해 주면 되고
Crawler가 이 DB 안에 테이블들을 자동으로 생성해 줍니다 실행 주기는 필요할 때만 수동 실행하는 On demand로 둡니다

최종적으로 검토해 본 뒤 생성해 줍니다.
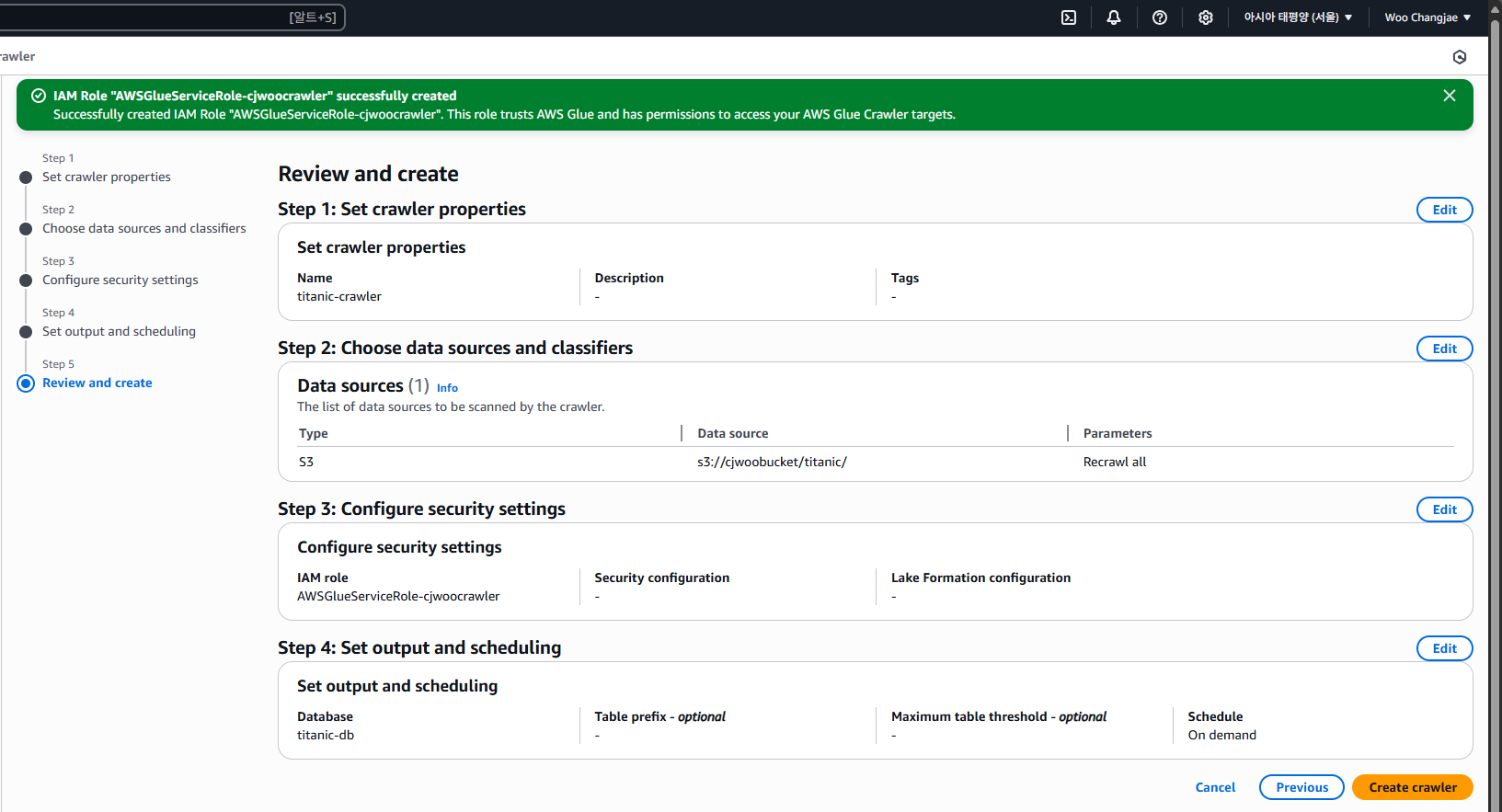
Glue Crawlers 실행 및 테이블 생성
이제 데이터를 긁어오기 위해 Run Crawler 버튼을 눌러 실행해 줍니다
누르면 자동으로 S3 경로에 있는 데이터를 읽어서 Glue Data Catalog에 테이블 스키마를 만들어줍니다


Amazon Athena 생성 및 실행
Crawler 실행이 끝났으면 이제 Athena로 넘어갑니다 [S3 + Glue + Athena] 조합의 마지막 단계입니다.

이제 본격적으로 Athena에서 쿼리를 날려보겠습니다
좌측에서 데이터 원본은 기본으로 있는 AwsDataCatalog,
데이터베이스는 우리가 Glue에서 지정해 뒀던 titanic-db를 선택해 주면 됩니다.
테이블도 자동으로 잘 생성돼 있고 titanic 테이블 클릭해서 스키마 확인한 뒤,
SELECT * FROM "titanic-db"."titanic" LIMIT 10;위와 같이 쿼리를 실행하니 잘 뜨는 것을 볼 수 있었습니다.
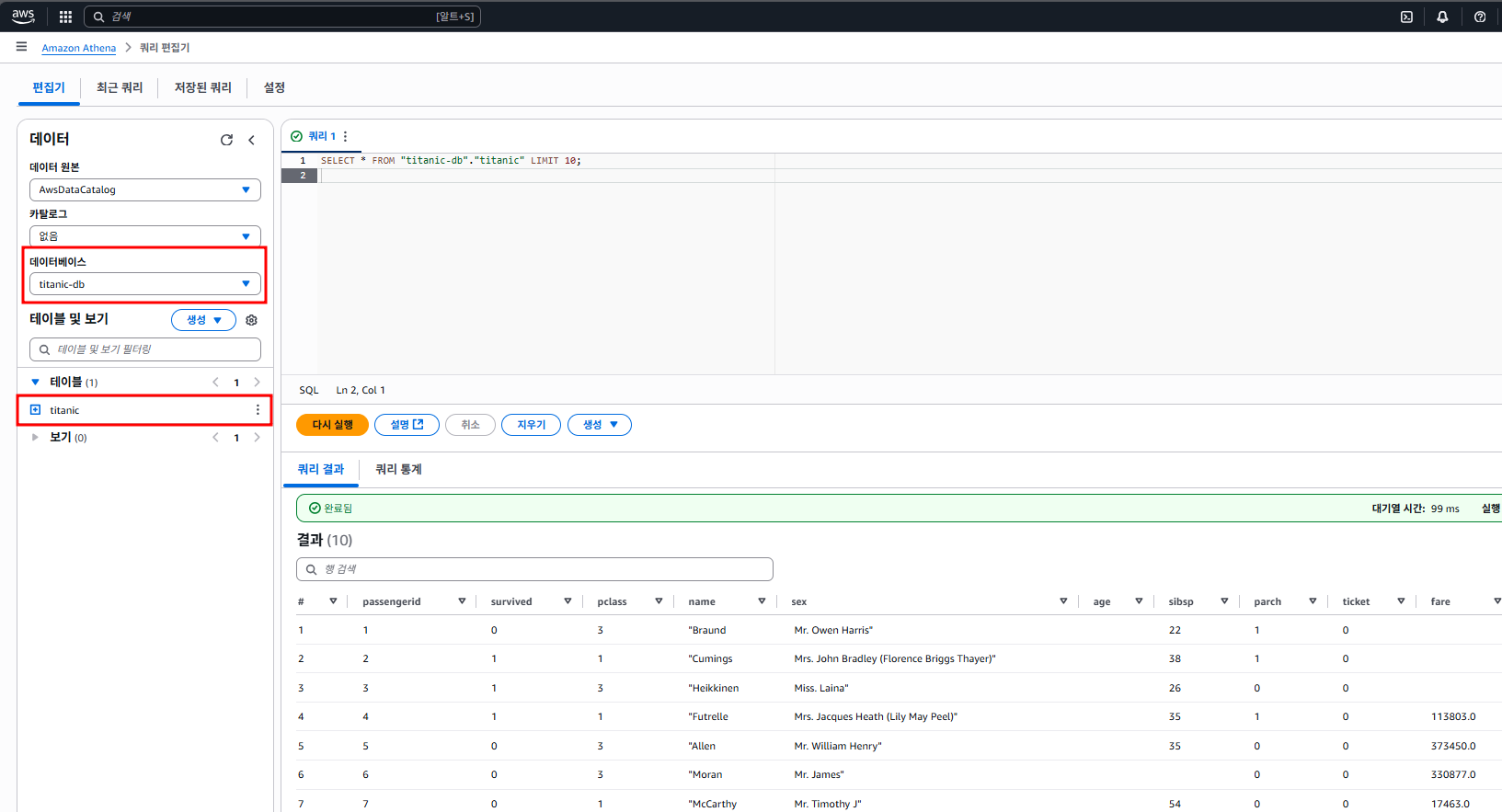
이제부터는 S3에 있는 CSV 데이터를 자유롭게 SQL로 분석할 수 있습니다.
AWS 첫 포스팅입니다.
다음 편에서는 Azure Databricks와 대응되는 AWS로 포스팅하겠습니다.
<참고자료>
크롤러를 사용하여 데이터 카탈로그 채우기 - AWS Glue
크롤러를 사용하여 데이터 카탈로그 채우기 - AWS Glue
크롤러를 사용하여 데이터 카탈로그 채우기 AWS Glue 크롤러를 사용하면 데이터베이스 및 테이블을 사용하여 AWS Glue Data Catalog를 채울 수 있습니다. 대부분의 AWS Glue 사용자가 사용하는 기본적인
docs.aws.amazon.com
'AWS > AWS Database Servises' 카테고리의 다른 글
| AWS Glue Job + PySpark로 타이타닉 데이터 분석하기 (1) | 2025.07.14 |
|---|
Azure 가격 계산기 활용법
1. 개요:
Azure나 AWS를 사용할 때 가장 주의해야 할 점은 비용입니다.
테스트용으로 서비스를 실행시킨 상태로 어디 잠깐 여행이라도 갔다온다면 꽤나 가슴 아픈 경험을 하게 될 수도 있고
클라우드 비용은 사용량에 따라 변동되기 때문에 예상 비용을 미리 계산하는 게 필수인데요
이 도구를 활용한다면 예상 사용량을 기반으로 미리 비용을 계산하고 다양한 절감 방법도 고려할 수 있습니다.
2. 구성 요소:
Azure의 대표적인 리소스는 다음과 같이 비용이 달라집니다
Virtual Machines (VM) : CPU, RAM, OS, 리전에 따라
Storage : 디스크 유형(SSD/HDD), 크기, 사용량에 따라
Networking : 아웃바운드 데이터 전송량에 따라
세부 구성 요소
| 요소 | 설명 |
| 리전 | 데이터 센터 위치에 따라 |
| 사용 시간 | 실행한 시간 만큼 |
| 예약 인스턴스 | 길게 예약 시 할인 적용 커짐 |
| 스팟 인스턴스 | 일시적으로 저렴한 가격으로 사용 가능 |
| 스토리지 종류 | Standard HDD < Standard SDD < Premium SSD |
| 트래픽 비용 | 인바운드 (무료) ㅡ 아웃바운드 (유료) |
3. 진행 과정:
가상 머신 가격 계산하기
Azure의 대표적인 가상 머신을 추가했을 때 가격 계산을 해보겠습니다.

가격 계산기 | Microsoft Azure
특정 시나리오의 Azure 제품 및 기능을 구성하고 해당 비용을 예측하세요.
azure.microsoft.com
가격계산기 접속한 후 가상 머신을 클릭해주면

밑에 상세하게 설정할 수 있는 창이 나오고 표시된 것처럼 절약 플랜을 쓴다거나, 예약, 스팟 인스턴스 사용 시
비용 절감이 가능하다는 것을 확인할 수 있습니다.

라이선싱 프로그램이라고 맨 밑에서 4가지 정도를 볼 수 있는데요
MCA 는 Microsoft 고객 계약
EA는 기업 계약
CSP는 클라우드 솔루션 공급자이고
MOSA는 온라인 정기가입 예약 이라고 합니다 참고하면 될 듯 합니다.
이상 간단하게 가격 계산기에 대해서 알아봤는데요
Azure Cost Management나 온프레스 vs Azure 비용 비교(TCO 계산기) 에 대해서도 천천히 다뤄보도록 하겠습니다
'Azure > Azure Overview & Infrastructure' 카테고리의 다른 글
| Azure TCO 계산기 (0) | 2025.02.10 |
|---|---|
| AzCopy 실습 (3) | 2024.12.31 |
| Azure Storage 계정 생성 및 업로드 (0) | 2024.12.30 |
| Azure Stoarge 개요 (2) | 2024.12.30 |
| Azure Kubernetes and Container 생성 (2) | 2024.12.16 |
IIS 이중화 (On-premise)
1. 개요:
웹 서비스의 가용성과 안정성을 높이기 위해 IIS는 보통 이중화를 많이 하는데요
특히 대규모 트래픽이 있다거나 할 때는 반 필수적이라고 볼 수 있습니다.
이 포스팅에서는 On-premise 환경의 IIS 이중화만 다룰 것이고
Azure Load Balancer 를 이용한 IIS 이중화는 Azure 카테고리에서 해야되...나?
아무튼 빠른 시일 내에 클라우드 환경에서의 이중화도 다루겠습니다. (AWS 포함)
개인적으로 제 블로그에도 대규모 트래픽이 왔으면 좋겠습니다
2. 구성 요소:
오늘도 역시나 회사 MDS 서버의 VM 2대 입니다.
VM(left) : IIS1 ,Windows server 2022 ENG, 10.10.5.8
VM2(right) : IIS2 , Windows server 2022 KOR, 10.10.5.6
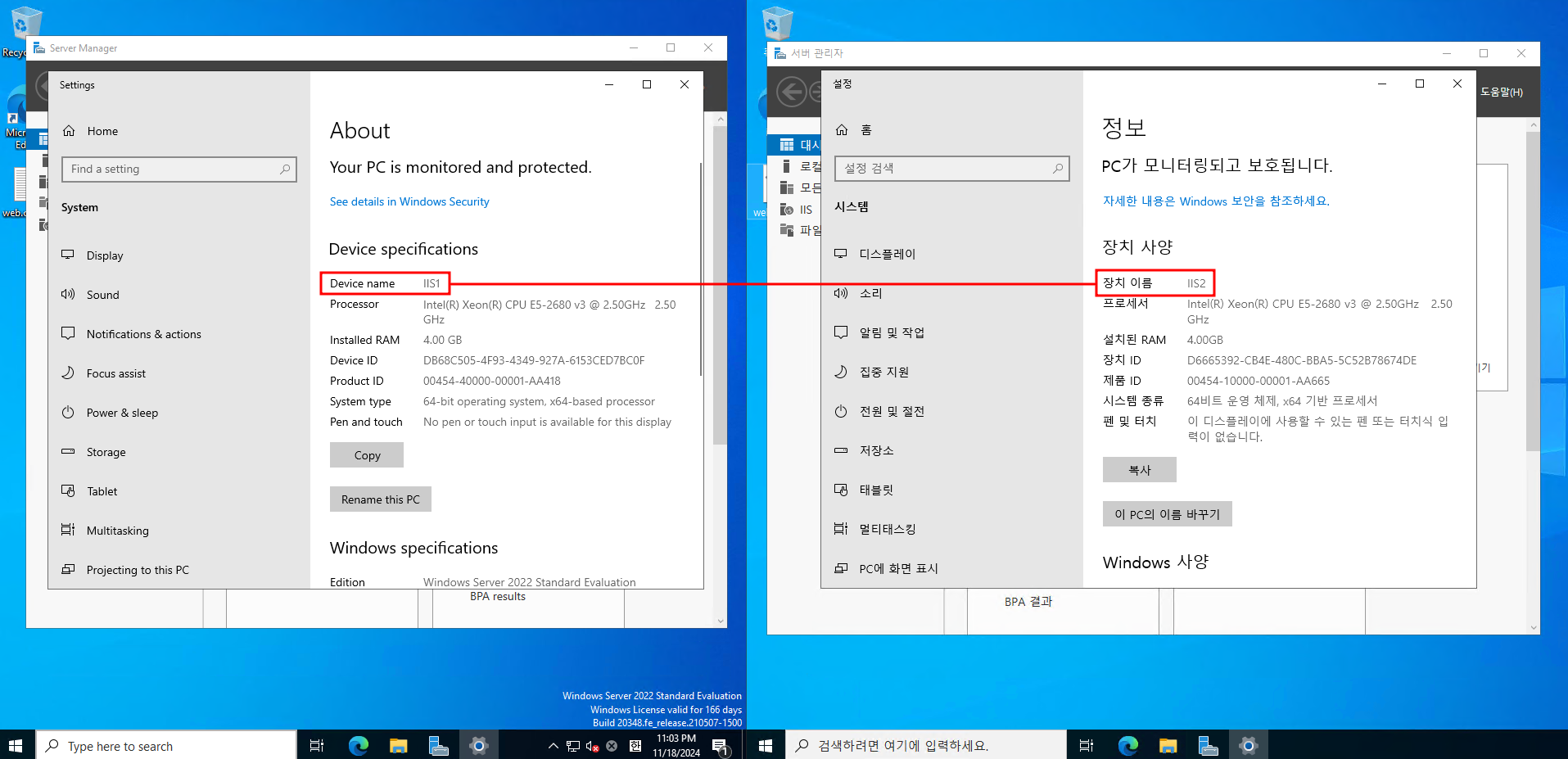
3. 진행 과정:
- Netowrk Load Balancer 설정

서버 관리자 → 역할 및 기능 추가 → 기능 목록에서 Network Load Balancing 을 선택하고 설치합니다.

NLB 관리를 검색창에 검색을 하든...해서 실행합니다.
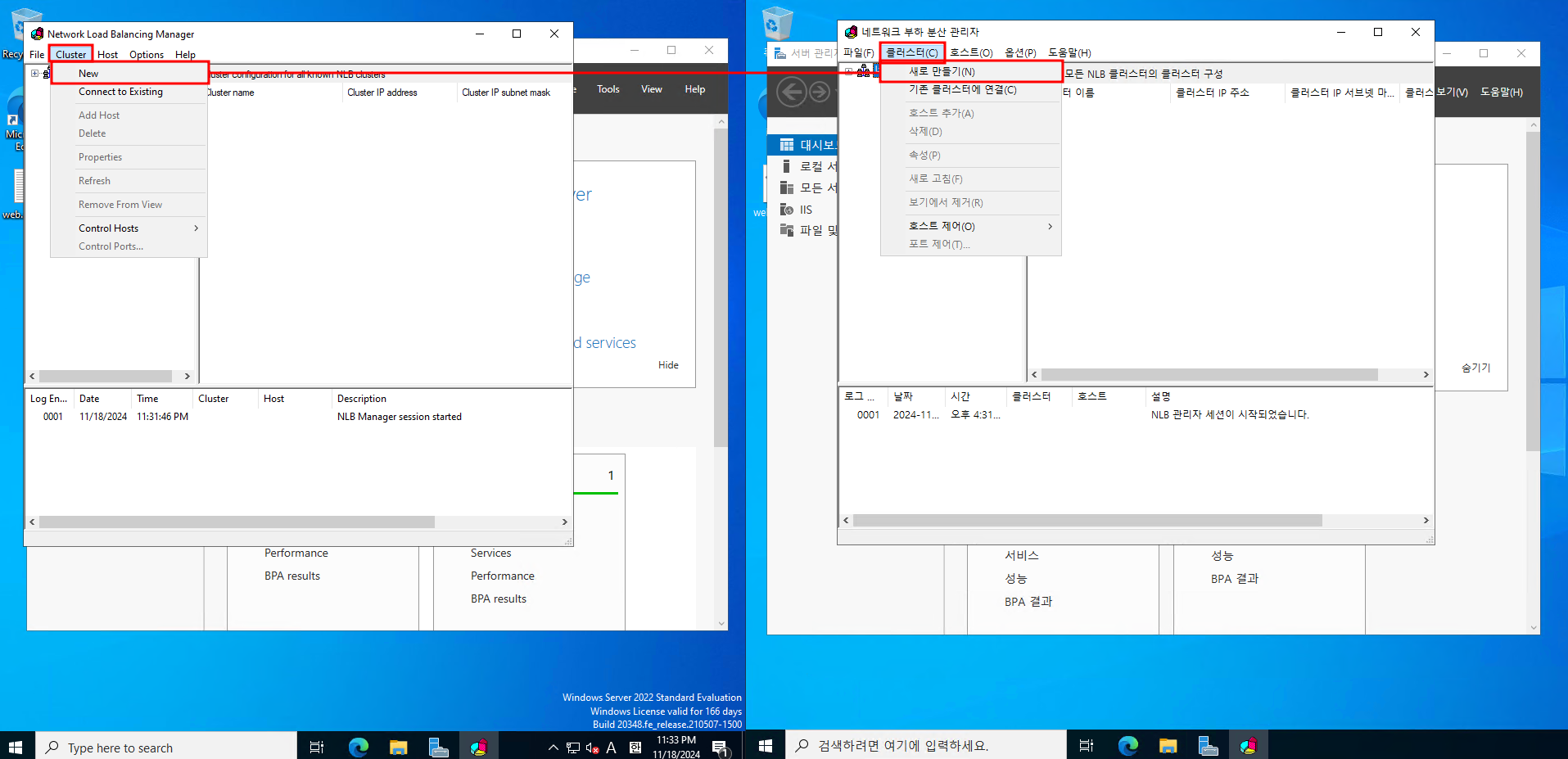
새 클러스터를 생성합니다

각 호스트 IP에는 각 VM의 ip를 넣습니다

VIP에는 두 VM의 IP가 동일하게 설정합니다
(VIP는 부하 부산 클러스터에 넣는 공통 IP 주소 입니다.
외부에서 봤을 때는 두 개의 서버가 아닌 하나의 서버로 보이는 거죠.)
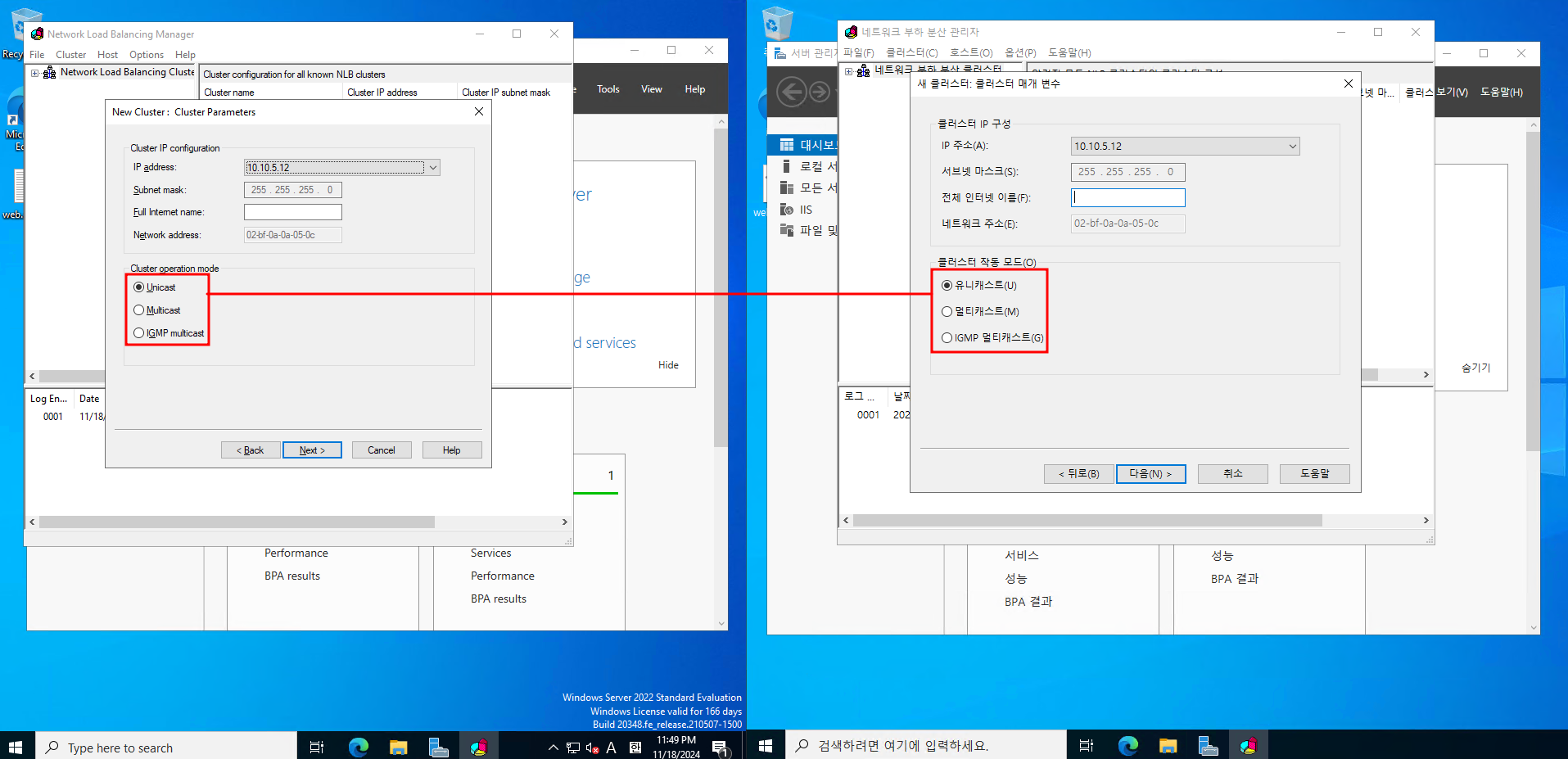
클러스터 모드가 있는데요
Unicast 모드는 모든 클러스터 노드가 동일한 MAC 주소를 공유하도록 하는겁니다 보통 소규모 환경에서 구성합니다
Multicast 모드는 클러스터 노드들이 고유한 멀티캐스트 MAC 주소를 사용하여 작동합니다 대규모 환경에서 구성합니다.
- 이슈 발생
그러나 그 전에 NLB를 설치 한 후에 몇가지 문제가 생겼습니다.
① IIS1, IIS2 에서 인터넷이 안됨
이건 문제는 100% 장담은 못하지만, 회사의 장비 문제였던 것으로 추정되는데요
위에서 설정했던 유니캐스트 모드를 멀티캐스트 모드로 바꾸니 ping 8.8.8.8 이 두 VM에서 잘 실행되었습니다.
유니캐스트 모드에서는모든 서버가 같은 MAC 주소를 사용하게 되어서 네트워크 장비에서 이를 인식하고 처리하는데 장애가 생길 수도 있습니다.
멀티캐스트 모드는 각 서버에 고유한 MAC 주소를 할당하기 때문에 가능했던 것으로 추정됩니다
② IIS1 과 IIS2 간의 통신이 안됨
이 부분은 방화벽에서 TCP/UDP 2500-5000 대를 추가하니 해결되었습니다.

- DFS 설치
그 전에 DFS 복제는 AD 도메인 환경에서 진행해야 합니다
NLB(Network Load Balancing)**가 웹 트래픽을 분산하는 역할만 하므로, 웹 서버 간의 데이터 동기화를 위해서는 DFS 같은 파일 공유 시스템이 필요합니다.

똑같이 서버 관리자에서 DFS 복제 체크를 하고 진행해줍니다
DFS 역할은 네트워크 상에서 데이터를 동기화하거나 공유할 때 사용되므로,
설치 과정을 동일하게 IIS1과 IIS2에서 반복합니다.

설치가 완료되었으면 DFS 관리를 클릭합니다.

DFS 관리에서 새 복제 그룹을 클릭합니다.

다목적 복제 그룹을 선택하고 진행합니다.

이름은 그냥 WebContentReplication 이렇게 했고
도메인은 join 시킨 sangju.run.place 라고 디폴트 설정 되어있습니다

이런 식으로 IIS1과 IIS2를 복제 그룹에 추가해줍니다.

기본인 전체 매시를 선택합니다.

복제 일정은 항상 활성화로 했습니다 (특정 시간에만 실행하도록 설정 가능합니다.)
주 구성원은 저는 IIS1으로 설정했습니다.

복제할 폴더를 선택할 때는 웹 페이지의 구성 요소가 있는 폴더로 선택했고
IIS1, IIS2 모두 경로가 동일해야합니다

IIS1이 주 구성원으로 되어있는 것을 확인하고
구성원 IIS2의 로컬 경로를 아까 복제할 폴더의 로컬 경로와 똑같이 설정하고 구성원 자격 상태는 사용함 으로 설정합니다.

이렇게 한 후 wwwroot 루트에 똑같은 파일이 복사가 되었다면 완료 입니다.
어찌저찌 온프레미스 환경의 IIS 이중화가 완료되었습니다
하이브리드 IIS도 있다는데 과연 하이브리드로 구성한 환경이 많을까... 싶기는 한데
하이브리드 AD도 하는김에 같이 IIS도 해보겠습니다.
이론 상 대충 비슷하지 않을까 싶습니다
'Microsoft 365' 카테고리의 다른 글
| Exchange Server 설치 (2) | 2024.12.06 |
|---|---|
| Hybrid AD 구축 (1) | 2024.11.29 |
| AD 이중화 (On-premise) (4) | 2024.11.18 |
| 3-Tier 구축 방법 4단계 - SQL-IIS 연동 (2) | 2024.11.13 |
| 3-Tier 구축 방법 3단계 - MS-SQL 설치 (4) | 2024.11.12 |
3-Tier 구축 방법 1단계 - AD 구축과 join
3티어 아키텍처 구축은 웹 서버(IIS), 데이터베이스 서버(MS-SQL), 그리고 인증 및 권한 관리(Active Directory)를 각기 다른 계층으로 나누어 구성하는 방식입니다.
각 계층 별로 상세히 구성하는 방법을 포스팅하도록 하겠습니다.
전체적인 단계는
AD 구축
1. 개요:
Active Directory(AD)는 사용자와 권한을 관리하는 서비스입니다. 인증 및 액세스 권한을 처리하는 역할을 담당하므로, 네트워크나 애플리케이션에 대한 접근 제어를 쉽게 설정할 수 있습니다.
2. 환경구성:
- Windows Server에 AD DS 설치

- AD 도메인 구성정보 입력
서버 매니저 → 알림 → Promote this server to a domain controller 클릭

새로운 Forerst 를 추가하고 Root Domain Name 입력 후 클릭
(내부 domain이므로 구입할 필요 없음)

복구 패스워드를 입력

AD join
DHCP 설정 시 1차 도메인은 앞서 설치한 AD 서버를 향하게 합니다

Active Directory Users and Computers 를 클릭하여 사용자 계정을 생성

아까 생성한 도메인(cjwoo.com) 로 생성된 기본 계정을 확인하고

Users → 새로 만들기 → 사용자 클릭

추가하려는 사용자 정보를 입력


Default 권한 확인

이제 AD를 join할 단말으로 넘어가서 AD join을 수행
설정 → 시스템 → 정보 → 고급 시스템 설정 → 컴퓨터 이름 변경

생성한 AD user 이름으로 입력 후 변경

net /domain user 명령어를 이용하여 AD 도메인에 정상 조인됨을 확인하면 완료됩니다.
여기까지 AD 구축과 AD join의 과정이었습니다.
이제 다른 학습 방향으로 나아갈 수 있는데
1. IIS, ms-sql 으로 3-tier 아키텍쳐를 구현하는 것
2. AWS, Azure로 3-tier를 구현하는 것
3. AD 이중화
4. Exchange 구축
등이 있습니다.
최근에 이러저러한 핑계로 블로그 작성이 나태했습니다
반성하면서 계속 나아가도록 하겠습니다.
'Microsoft 365' 카테고리의 다른 글
| AD 이중화 (On-premise) (4) | 2024.11.18 |
|---|---|
| 3-Tier 구축 방법 4단계 - SQL-IIS 연동 (2) | 2024.11.13 |
| 3-Tier 구축 방법 3단계 - MS-SQL 설치 (4) | 2024.11.12 |
| 3-Tier 구축 방법 2단계 - IIS 설치 (2) | 2024.11.06 |
| 3-Tier Architecture란? (1) | 2024.10.23 |
3-Tier Architecture란?
1. 3-Tier 아키텍쳐의 개념
3티어 아키텍쳐 구축은 웹 서버(IIS), 데이터베이스 서버(MS-SQL), 그리고 인증 및 권한 관리(Active Diretory) 를 각기 다른 계층으로 나누어 구성하는 방식입니다. 이 3계층은 다음과 같습니다
- Presentation Tier (프레젠테이션 계층) : 사용자 인터페이스를 제공하는 웹 서버나 클라이언트 어플리케이션, 사용자는 이 계층을 통해 시스템과 상호 작용합니다.
- Logic Tier (애플리케이션 로직 계층) : 비즈니스 로직과 규칙을 처리하는 계층, 웹 서버와 데이터베이스 사이에서 데이터를 처리하고, 응답을 생성하는 역할을 합니다.
- Data Tier (데이터 계층) : 데이터베이스 서버로서, 데이터를 저장하고 관리하는 역할 및 처리를 합니다.
2. 3-Tier 아키텍쳐의 목적
3티어 아키텍처의 핵심 목적은 확장성, 유지보수성, 보안성을 극대화하면서 애플리케이션을 효과적으로 분리하는 것입니다.
a) 분리된 책임과 관리
- 각 계층은 서로 독립적으로 기능하므로 시스템을 확장하고 관리하는데 용이합니다.
- 프레젠테이션 계층(UI), 애플리케이션 로직 계층, 데이터베이스 계층을 분리함으로써, 각 계층의 변경이 다른 계층에 미치는 영향을 최소화할 수 있습니다
b) 확장성 (Scalability)각 계층을 독립적으로 확장할 수 있습니다. 예를 들어 트래픽이 많아지면 프레젠테이션 계층(IIS 서버)를 여러 대 배포하거나, 데이터가 증가하면 데이터베이스 서버(MS-SQL)를 확장하여 성능을 유지할 수 있습니다.
c) 보안성 강화
3티어 구조는 보안 강화를 용이하게 합니다. 각 계층 간에 보안 규칙을 적용할 수 있으며, 특정 계층에서만 접근 가능한 리소스를 제한할 수 있습니다.
d) 유지보수성
계층화된 구조 덕분에, 애플리케이션의 어느 한 부분을 변경하거나 업그레이드할 때 전체 시스템을 중단할 필요가 없습니다.
e) 유연성
각 계층이 명확히 분리되어 있어, 다른 기술 스택을 도입하거나 변경하는 것이 용이합니다.
현재는 IIS를 사용하지만, 다른 웹 서버(Apache, Nginx 등)로 전환하거나, MS-SQL을 다른 DBMS(MySQL, PostgreSQL 등)로 바꿀 수 있습니다
3. 3-Tier와 클라우드 환경
클라우드 환경에서는 이 아키텍처를 가상화하거나 컨테이너화하여 클라우드 서비스에서 쉽게 배포할 수 있습니다
- AWS : EC2, RDS, ELB등을 사용하여 확장 가능한 3티어 아키텍쳐 구현
- Azure : VM, SQL, Azure AD를 이용해 구축
Azure와 AWS에서의 3티어 아키텍쳐 구현 비교
| 서비스 | Azure | AWS |
| Actice Directory | Azure AD or VM에서 AD DS | EC2에서 AD |
| IIS | Azure VM or Azure App Sevice | EC2 or Elastic Beanstalk |
| MS-SQL | Azure SQL Database or VM에서 SQL server | Amzon RDS for SQL Server or EC2에서 SQL Server |
일단은 Azure를 이용하여 VM에서 3티어 구축을 먼저 해본 뒤, AWS 상으로도 해볼 예정입니다.
SQL이 사실상 문외한이라서 조금 공부가 필요할 듯 싶습니다.
'Microsoft 365' 카테고리의 다른 글
| AD 이중화 (On-premise) (4) | 2024.11.18 |
|---|---|
| 3-Tier 구축 방법 4단계 - SQL-IIS 연동 (2) | 2024.11.13 |
| 3-Tier 구축 방법 3단계 - MS-SQL 설치 (4) | 2024.11.12 |
| 3-Tier 구축 방법 2단계 - IIS 설치 (2) | 2024.11.06 |
| 3-Tier 구축 방법 1단계 - AD 구축과 join (5) | 2024.11.04 |