Azure Machine Learning – Azure ML Designer란? 1편
1. 개요:
이전 포스팅에서 Azure ML데 대한 기본을 간단하게 알아봤습니다.
구성 요소 중 하나인 Azure Machine Learning Designer는
개발 지식 없이도 머신러닝 모델을 설게하고 학습할 수 있도록 해주는 친구인데요
Drag & Drop 이다보니 굉장히 편하게 사용할 수 있습니다
2. 구성 요소:
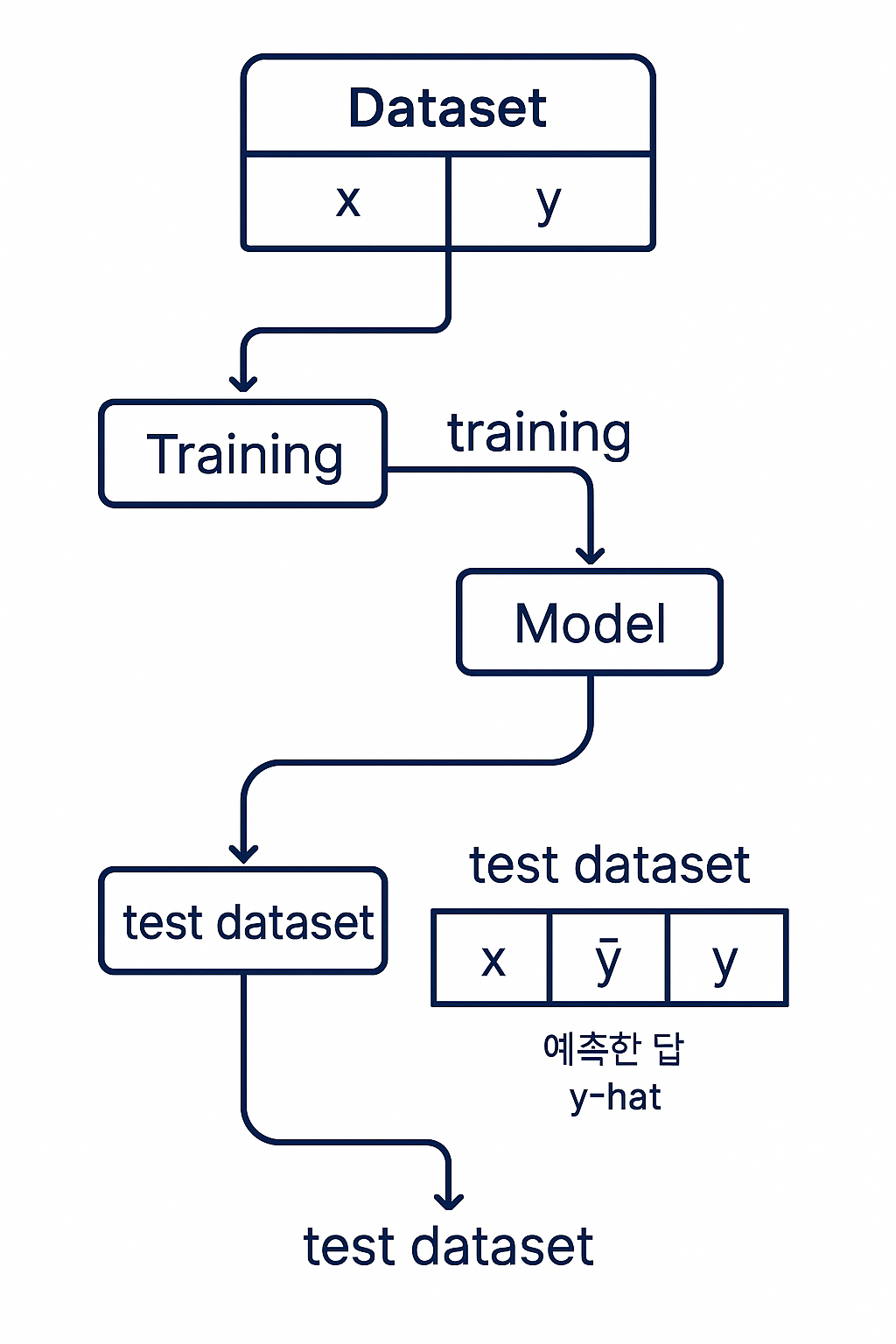
이 그림을 만들어준 ChatGPT에게 심심한 감사를 표하면서
먼저 머신러닝의 기본 흐름 그러니까 모델이 어떻게 학습하고 예측하는지에 대한 정의가 필요합니다
1) Dataset 구성
전체 데이터는 입력값 x와 정답 레이블 y로 구성되며
이 데이터를 학습용(train)과 테스트용(test)으로 나눕니다.
2) Training 단계
train dataset을 사용하여 모델을 학습합니다.
x값 y값 를 통해 패턴을 학습하게 됩니다.
3) Model 생성
학습이 완료되면 모델이 만들어지며, 이 모델은 x를 입력받아 y를 예측하는 함수가 됩니다.
4) 예측 및 평가
test dataset의 x를 모델에 넣어 예측값 ŷ(y-hat)을 얻고
이 ŷ를 실제 값 y와 비교하여 모델의 성능을 평가합니다. (정확도, AUC, RMSE 등등)
즉 정리하자면, 모델이 예측한 ŷ와 실제 정답 y의 차이를 줄이는 것이 머신러닝의 핵심이고
이 과정을 Azure ML Designer에서는 드래그 앤 드롭만으로 구현할 수 있는겁니다.
3. 진행 과정:
Computing Instance 만들기
Azure ML Studio에서 Designer를 실행하려면 먼저 컴퓨팅 리소스를 생성해야 합니다
모델 학습이나 실험에 사용할 VM인데요

리소스 그룹에서 생성하는 과정은 생략하도록 하겠습니다
Azure ML을 만들고 머신러닝 스튜디오로 들어온 후 왼쪽 메뉴의 컴퓨팅을 눌러 VM을 생성하도록 합니다
저는 가상 머신 유형은 CPU로 구성하고 크기는 스탠다드로 설정하였습니다
실습 환경에서는 저정도만 해도 충분합니다

다른 설정은 디폴트로 두고 쭉쭉 클릭하여 넘어간 뒤
이렇게 머신러닝 스튜디오 내에 컴퓨팅 인스턴스를 생성해주면 됩니다
이 친구가 모델에 대한 학습을 수행할 일종의 엔진 역할을 해줄겁니다
데이터셋 업로드 및 등록
자 이제 엔진을 만들었으니 본체를 만들어야겠죠
디자이너로 넘어와서 데이터 셋을 업로드 해보도록 하겠습니다.

이번에 사용할 데이터 셋은 타이타닉 데이터 입니다
솔직히 다들 쓰길래 저도 쓰고 있지만...좀 윤리적으로 어긋난 건 아닐까? 하는 생각이 듭니다
아무튼 Github의 titanic 데이터 셋 입니다
datasets/titanic.csv at master · datasciencedojo/datasets · GitHub
datasets/titanic.csv at master · datasciencedojo/datasets
A public repo of datasets. Contribute to datasciencedojo/datasets development by creating an account on GitHub.
github.com
잘 다운로드 받아서

Azure ML 스튜디오의 디자이너에서 위와 같이 플러스 버튼을 눌러 새 파이프라인을 시작합니다

파이프라인 편집기로 진입하면 다음과 같이 세 개의 주요 영역으로 나뉜 화면이 나타납니다.
| Tools (왼쪽) | 사용할 구성 요소(데이터셋, 모델, 전처리 도구 등)를 검색 및 선택 |
| Canvas (가운데) | 파이프라인을 직접 구성하는 드래그 & 드롭 영역 |
| Property (오른쪽) | 선택한 구성요소의 속성을 설정하는 공간 (예: 트리 수, 파라미터 등) |
구성 요소를 Tools에서 Canvas로 끌어다 놓는 것이 이 과정에 핵심 작업입니다

먼저 이전에 다운로드 받은 titanic 데이터 셋을 업로드 해주겠습니다.

다양하게 업로드 할 수 있습니다 저는 로컬 파일에서 업로드 해주겠습니다.
일반적으로 로컬에서 업로드된 파일은 Azure Blob Storage에 저장됩니다
같은 워크스페이스 내에서 여러 데이터 자산을 만들 경우, 저장소는 공유되기 때문에 프로젝트를 분리해서 관리하려면 별도 저장소를 만드는 것도 고려해야할 수도 있겠습니다
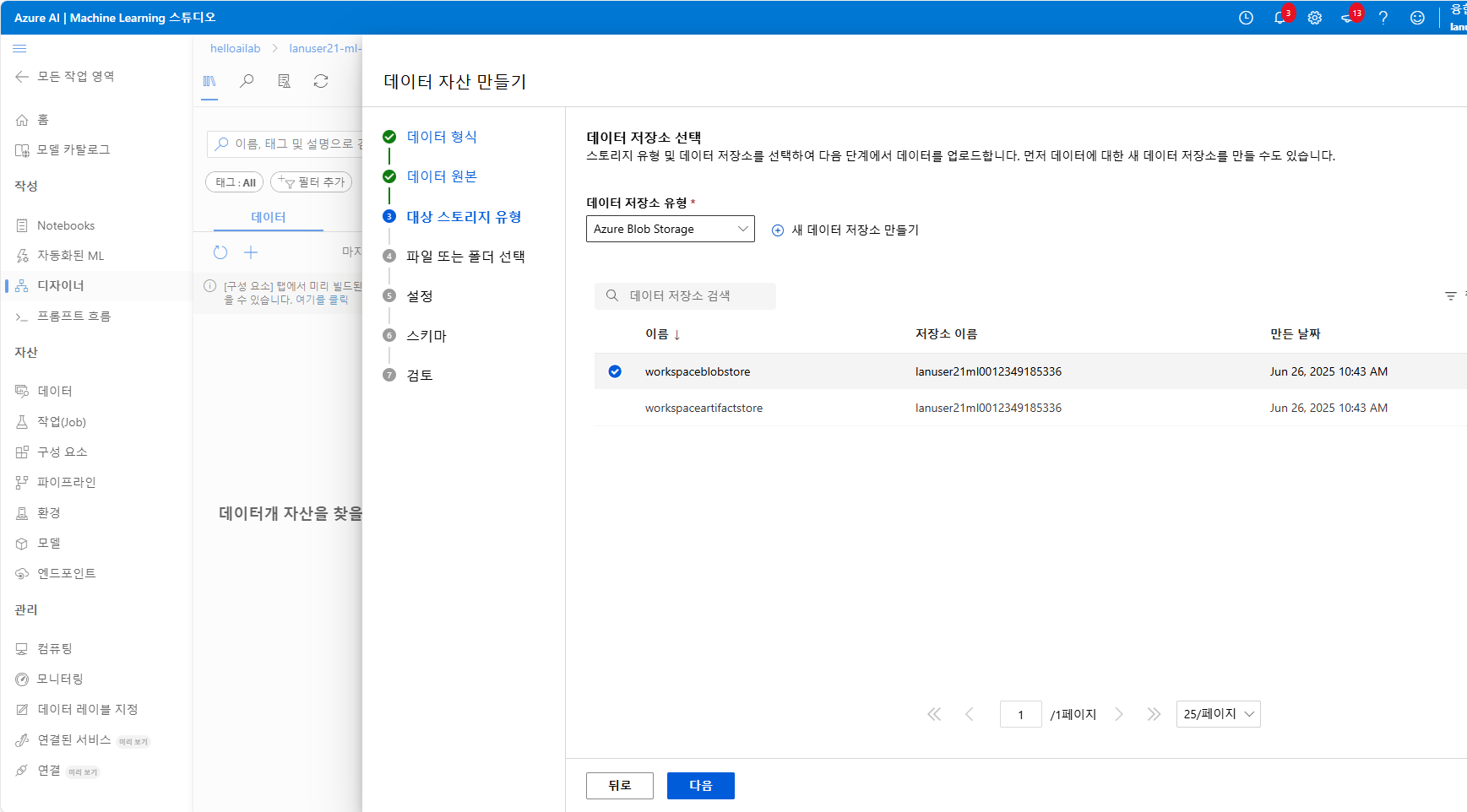
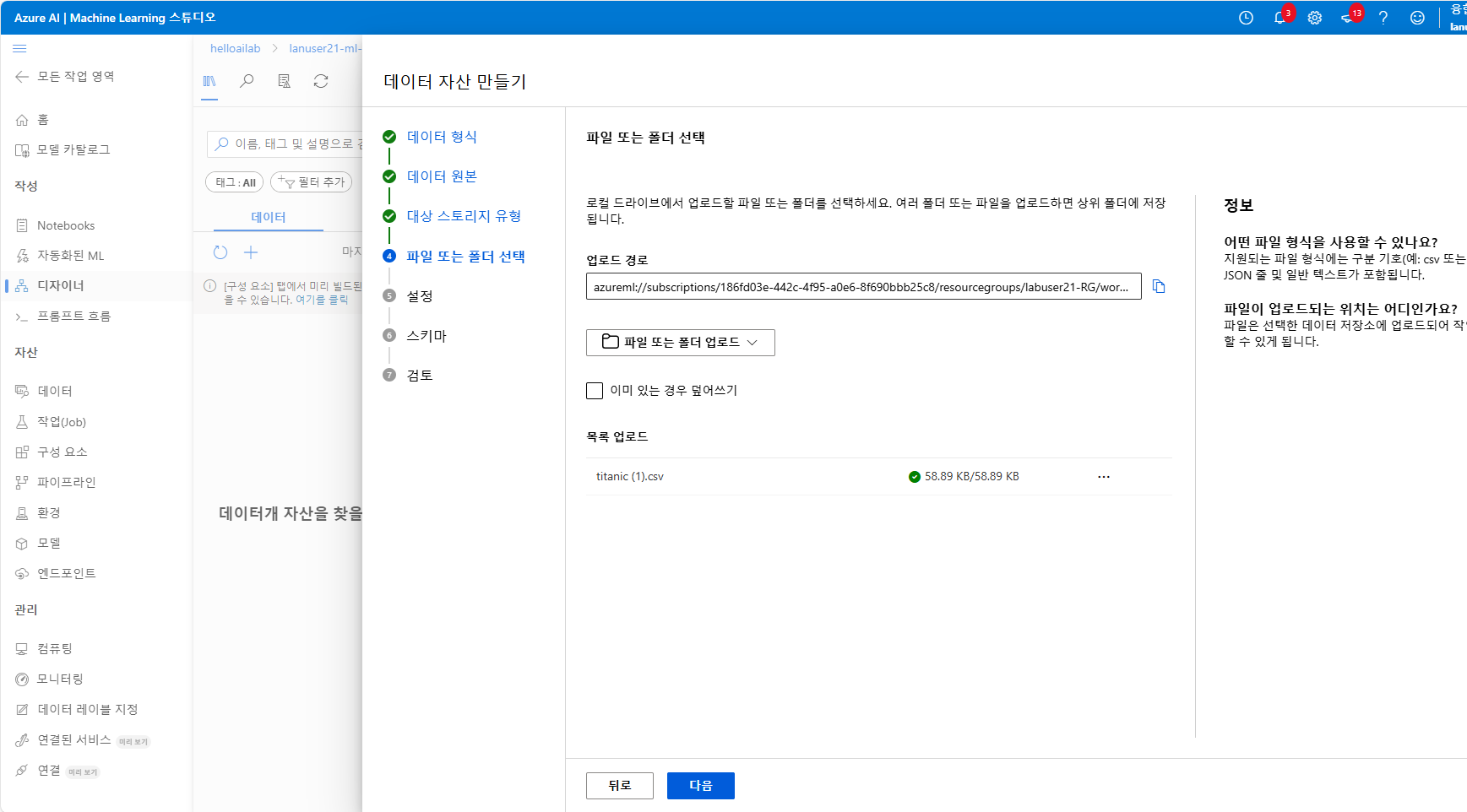
이런 식으로 데이터 셋을 업로드 하게 되면

저렇게 데이터를 업로드된 데이터를 미리보기로 확인할 수 있는데요

이번 과정에서 열은 생존 유무, 좌석 등그브 성별, 나이만 필요하므로
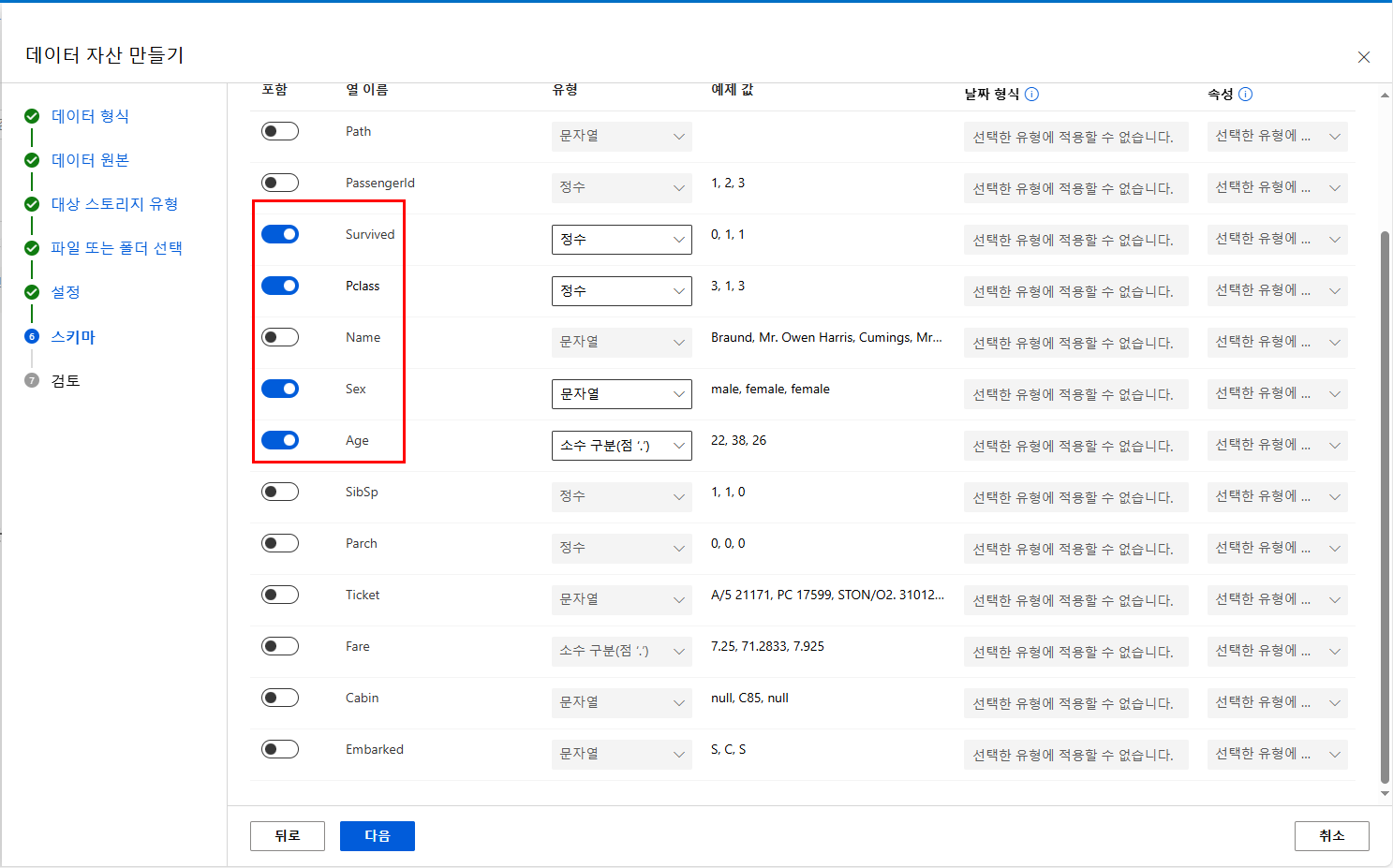
스키마에서 다음과 같이 열을 설정해주도록 합니다

그러나 중요한 점은 Survived 열에 대해서는 유형을 부울로 지정해야 합니다
Survived 열은 생존 여부를 0과 1로 나타내므로 데이터 타입을 부울(Boolean)로 지정하면 모델이
이 컬럼을 명확히 이진 분류(참 or 거짓)의 타깃으로 인식하게 됩니다.
파이프라인 구성
데이터셋 등록이 완료되면, 이제 학습 파이프라인을 구성합니다.
구성 요소 탭에서 드래그 & 드랍으로 시각적으로 워크플로우를 구성할 수 있습니다.

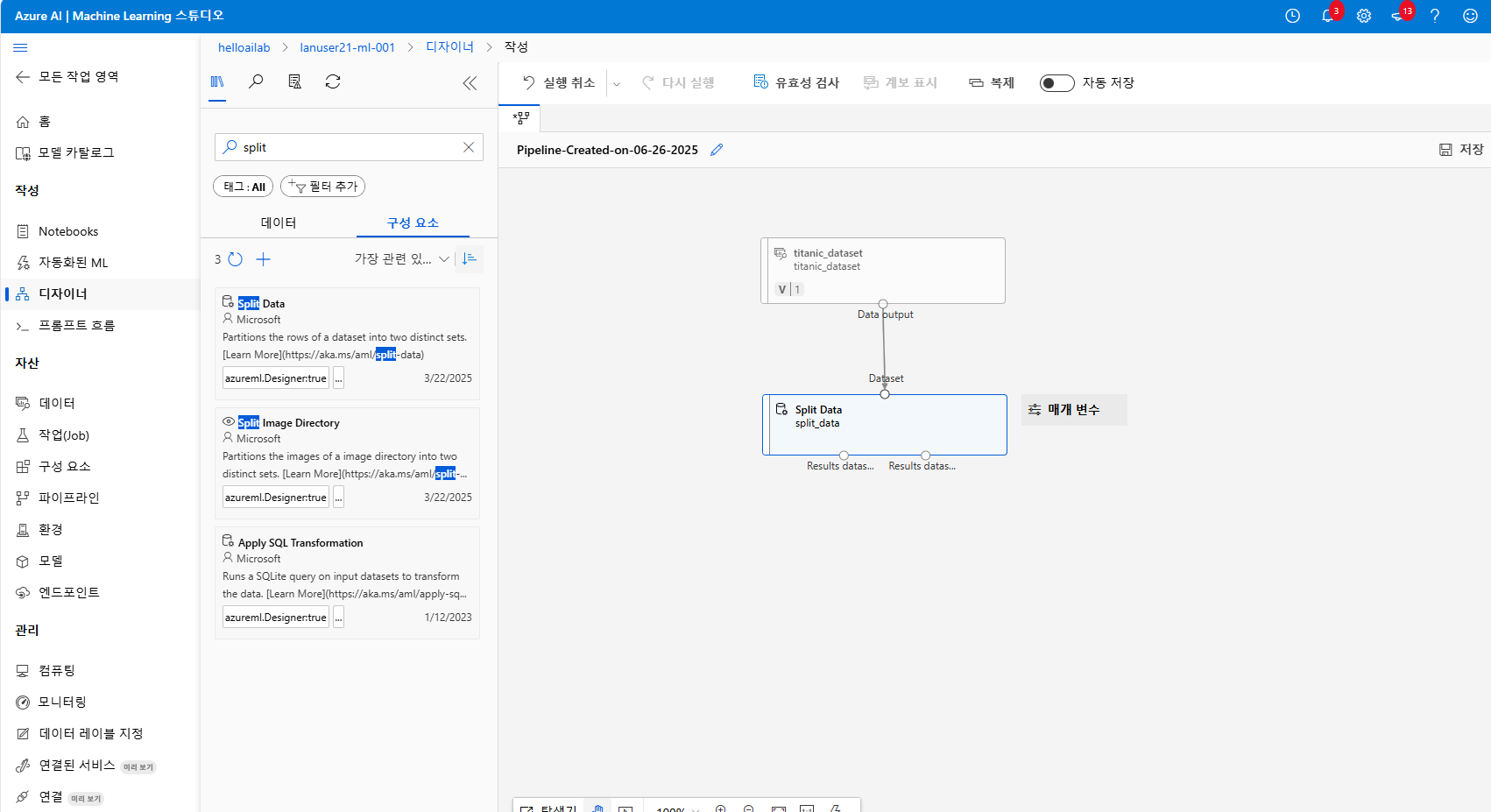
먼저 학습용 데이터와 테스트용 데이터를 나누기 위해 Split Data 블록을 사용합니다
보통 7대3 비율로 나누는 것이 일반적이긴한데 저는 그냥 8대2로 해보겠습니다.
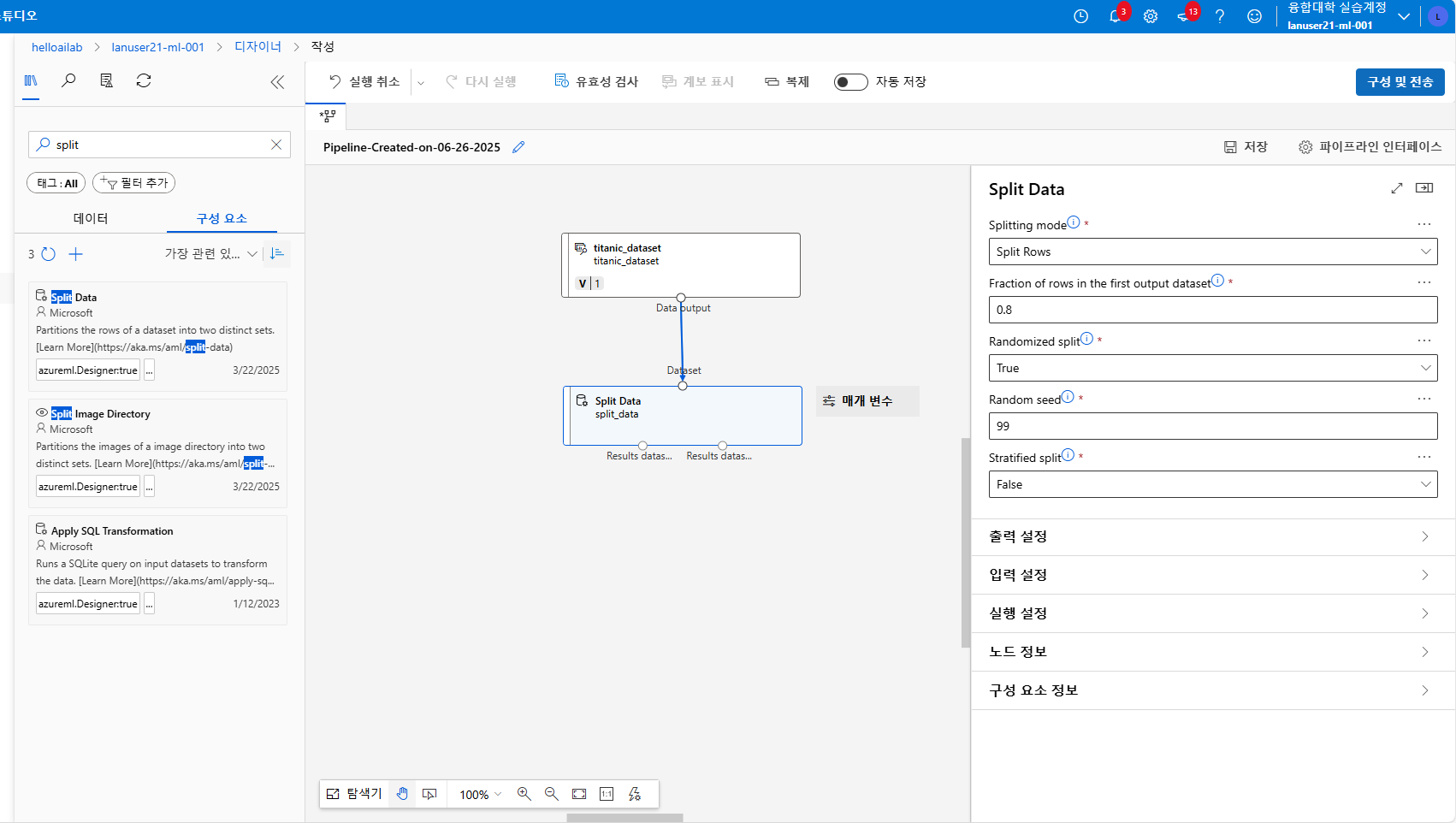
Fraction of rows 라는 건 전체 데이터의 80% 를 학습용으로 사용하겠다 라는 의미고
Random seed 는 표현이 좀 그렇지만 주머니 속의 돌을 맞추는 야바위할 때...주머니를 얼마나 흔들 것인가 에 대한 설정입니다.

그 다음 추가할 것은 생존과 죽음을 구분하는 Two-Class Decision Forest 알고리즘을 추가해주도록 합니다
이 알고리즘 블록을 Train Model 구성 요소와 함께 연결하여 학습을 진행하게 됩니다
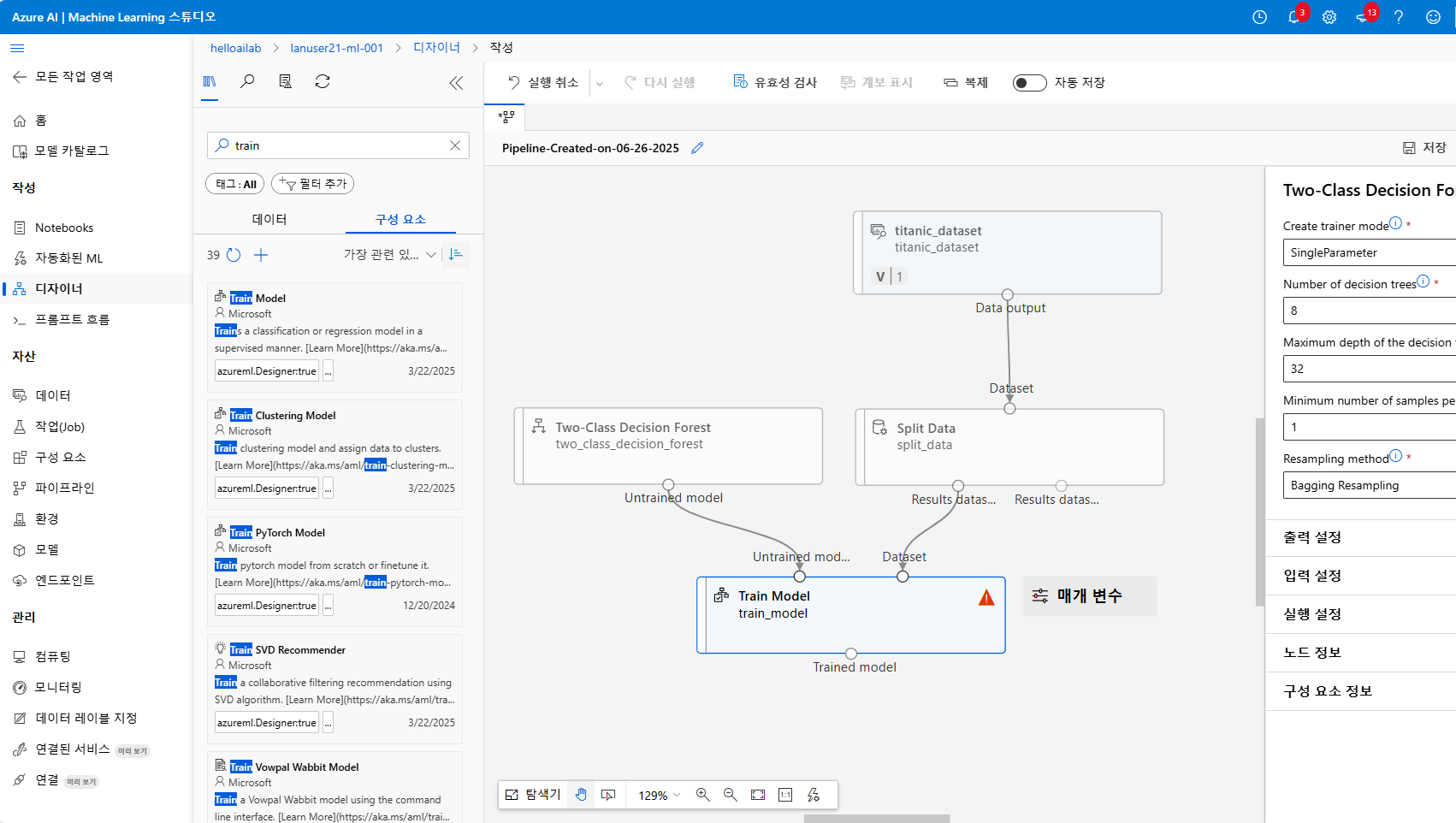
이제 Train 모델을 추가해서, 앞서 정의한 알고리즘과 학습 데이터를 연결합니다.
Train Model 구성 요소는 미학습 상태의 알고리즘과 학습용 데이터셋을 입력받아 실제 학습을 수행하는 핵심 블록..이라고 합니다
오른쪽 위에 아주 꺼림칙한 마크가 있는데요
아직 예측 대상 열(Target column) 을 지정하지 않았기 때문입니다.
Titanic 데이터셋 같은 경우는 Survived 열을 예측 대상으로 설정해야 하며, 이는 다음 단계에서 수행합니다.
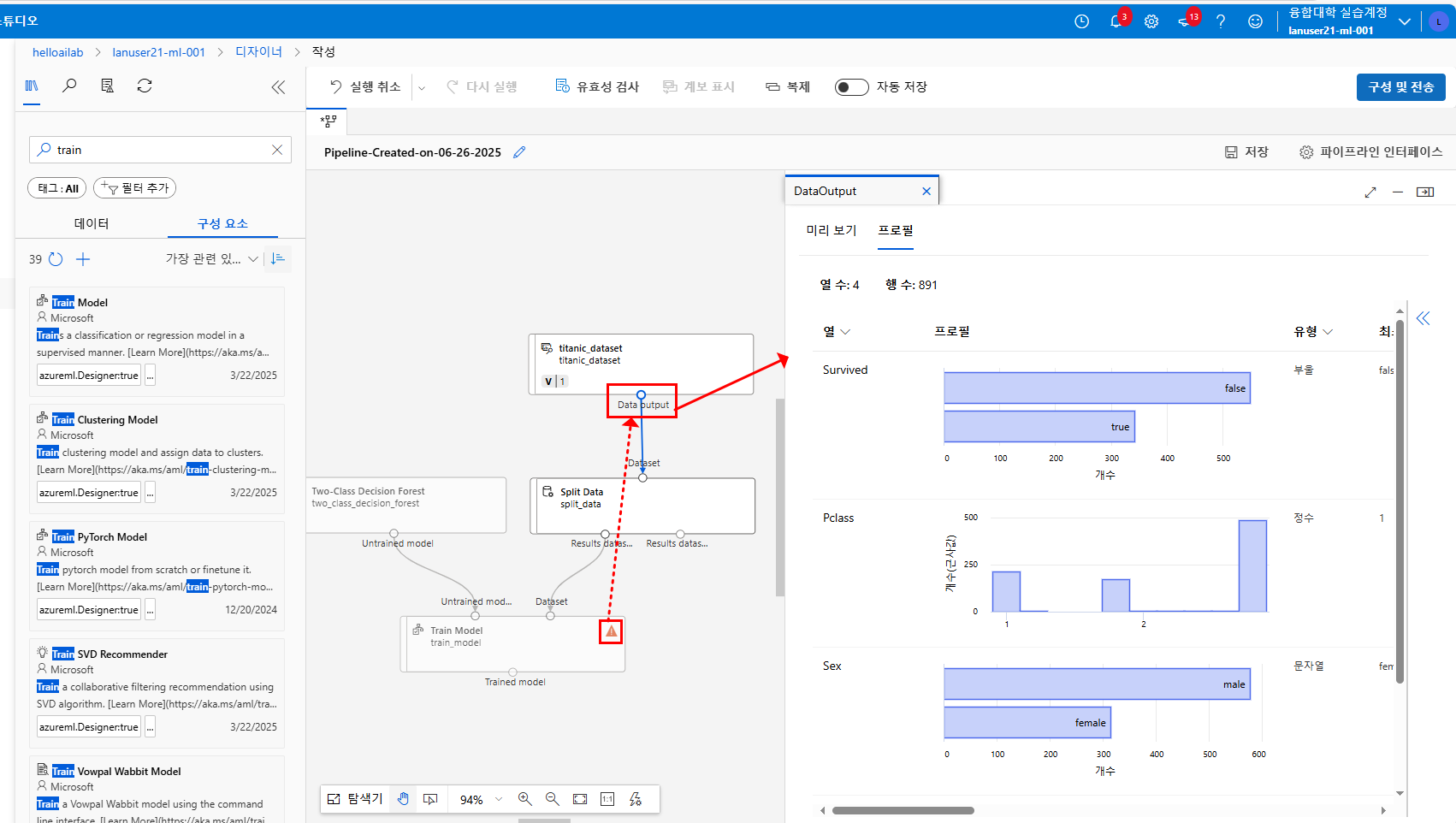


먼저, 앞서 연결한 Two-Class Decision Forest 알고리즘과 훈련용 데이터(Split Data 모듈의 첫 번째 출력)를 Train Model 모듈에 연결합니다.
이어서 Label column 항목을 설정해야 하는데,
타이타닉 데이터셋의 Survived 열이 예측 대상(label)이므로 해당 열을 선택합니다.

쟈란 깔끔해졌습니다!
2편에 계속...
'Azure > Azure AI & Machine Learning' 카테고리의 다른 글
| Azure Machine Learning – Notebook으로 IRIS 데이터 시각화 (1) | 2025.07.03 |
|---|---|
| Azure Machine Learning – Azure ML Designer란? 2편 (0) | 2025.06.30 |
| Azure Machine Learning이란? (0) | 2025.06.29 |
| Azure AI Search에 데이터 원본 연동 (4) | 2025.01.31 |
| 생성형 AI와 LLM (4) | 2025.01.17 |