Azure Machine Learning – Notebook으로 IRIS 데이터 시각화
1. 개요:
일단 제목부터 쉽지 않습니다.
Desktop은 뭐하지도 못하는 건가 싶을 수도 있는데요
당연히 그런건 아니고 Azure ML에는 Notebook이라고 Jupyter Notebook을 Azure 환경에 탑재한 버전이 있습니다.
Notebook은 개발 도구...라는 말이 틀린 말은 아니지만
좀더 정확하게는 데이터 분석과 흐름을 파악하는데 강점이 있는 도구라고 이해하면 됩니다
코드를 한 줄씩 실행하면서, 그 결과를 눈으로 바로 확인할 수 있고,
필요한 설명도 함께 적어둘 수 있기 때문에 일종의 데이터 실험 노트 같은 역할을 한다고 보면 됩니다
특히 Azure ML Notebook은
Azure 안에 있는 데이터셋이나 연산 자원, 학습 결과 등을 Notebook에서 바로 끌어다 쓸 수 있어서 훨씬 편합니다.
이번 글에서는 Azure ML Notebook을 사용해서 Iris 데이터셋을 시각화해 볼 겁니다.
Iris는 저같은 머신러닝 입문자들이 가장 많이 접하는 데이터셋인데요,
간단한 수치 데이터로 꽃의 품종을 구분할 수 있는지 분석해 보는 예제를 해보도록 하겠습니다.
이걸 Azure ML Notebook에서 직접 불러와서 데이터를 시각적으로 살펴보고
PCA라는 기법을 통해 시각화까지 해보는 겁니다.
2. 진행 과정:
※ 이전과 마찬가지로 Ml 스튜디오 내의 컴퓨팅 리소스가 필요합니다 이전 포스팅 참고해 주세요
Azure ML – Azure ML Designer란? 1편
새 Notebook 생성
ML 스튜디오에서 왼쪽은 Notebook을 클릭해 줍니다.
새로운 기능이 있다고 하는데 얼른 축하한다고 해주고 닫기를 눌러줍시다.
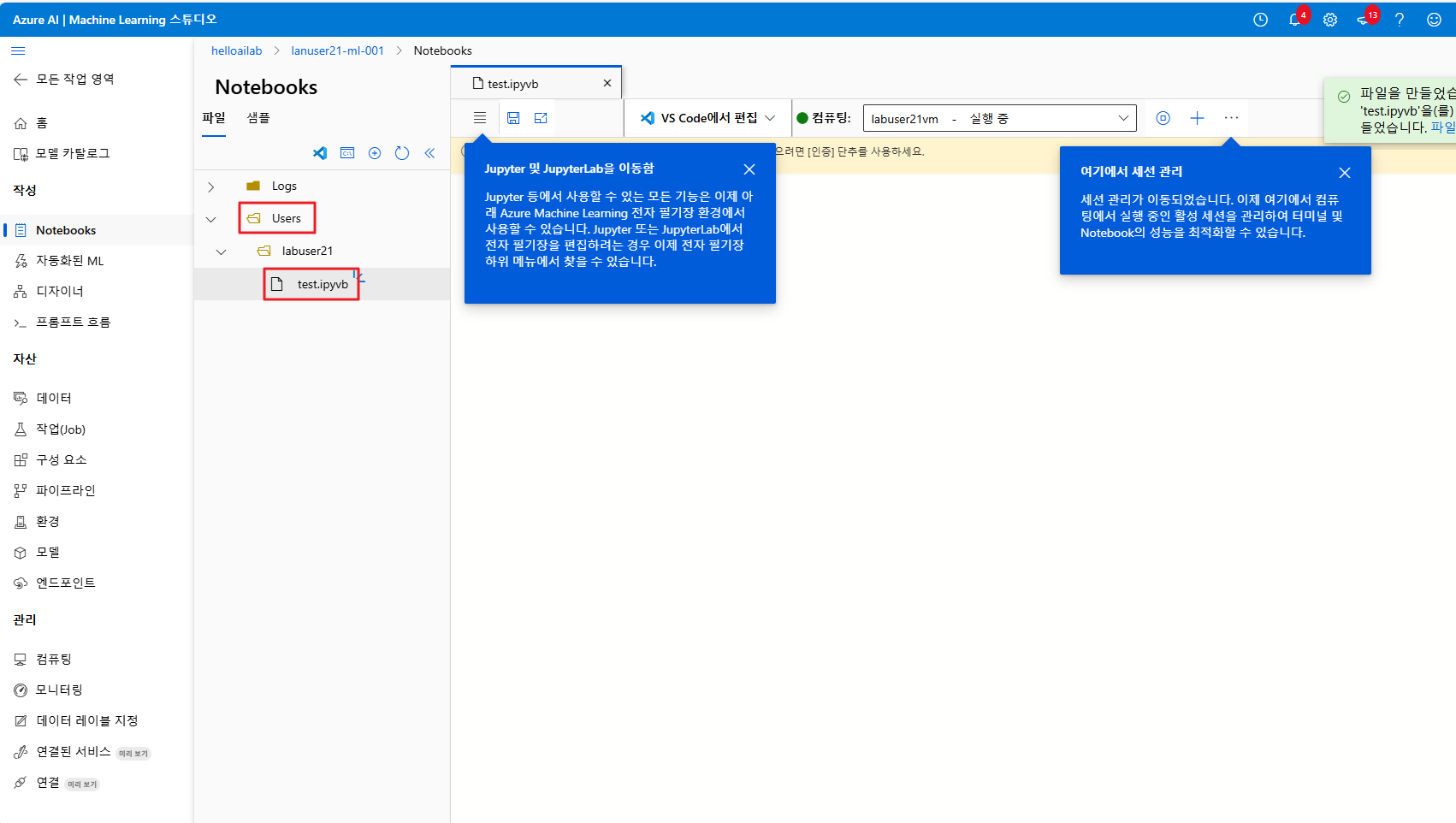
Users에서 새 파일 만들기를 클릭해서 파일을 만들어 줍니다
확장자는 .ipynb 로 해야 합니다
파일을 생성한 뒤 가장 중요한 것은 현재 컴퓨팅 인스턴스가 실행 중이어야 합니다.
인스턴스가 없다면 위의 링크를 통해 새롭게 생성하도록 합니다.
Notebook이 정상적으로 열리면 아래처럼 코드를 작성할 수 있는 환경이 준비됩니다.
커널 연결이 완료되면 좌측 상단에 컴퓨팅: [인스턴스명] - 실행 중으로 표시되고
첫 셀에서 바로 코드를 실행할 수 있습니다.
컴퓨팅에 인증되었습니다가 뜨면 준비가 되었습니다.
간단하게 Hello World부터 해보았습니다.
여담이지만, 우리가 아는 모든 게임, 프로그램 등이 처음에는 Hello World로 시작했다는 사실이
이 차가운 업계에서 보기 드문 갬-성이 아닐까 합니다.
Iris 데이터 불러오기 및 시각화
이제 본격적으로 코드를 작성해 보겠습니다.
from sklearn import datasets
iris = datasets.load_iris()이런 식으로 데이터를 불러와주고
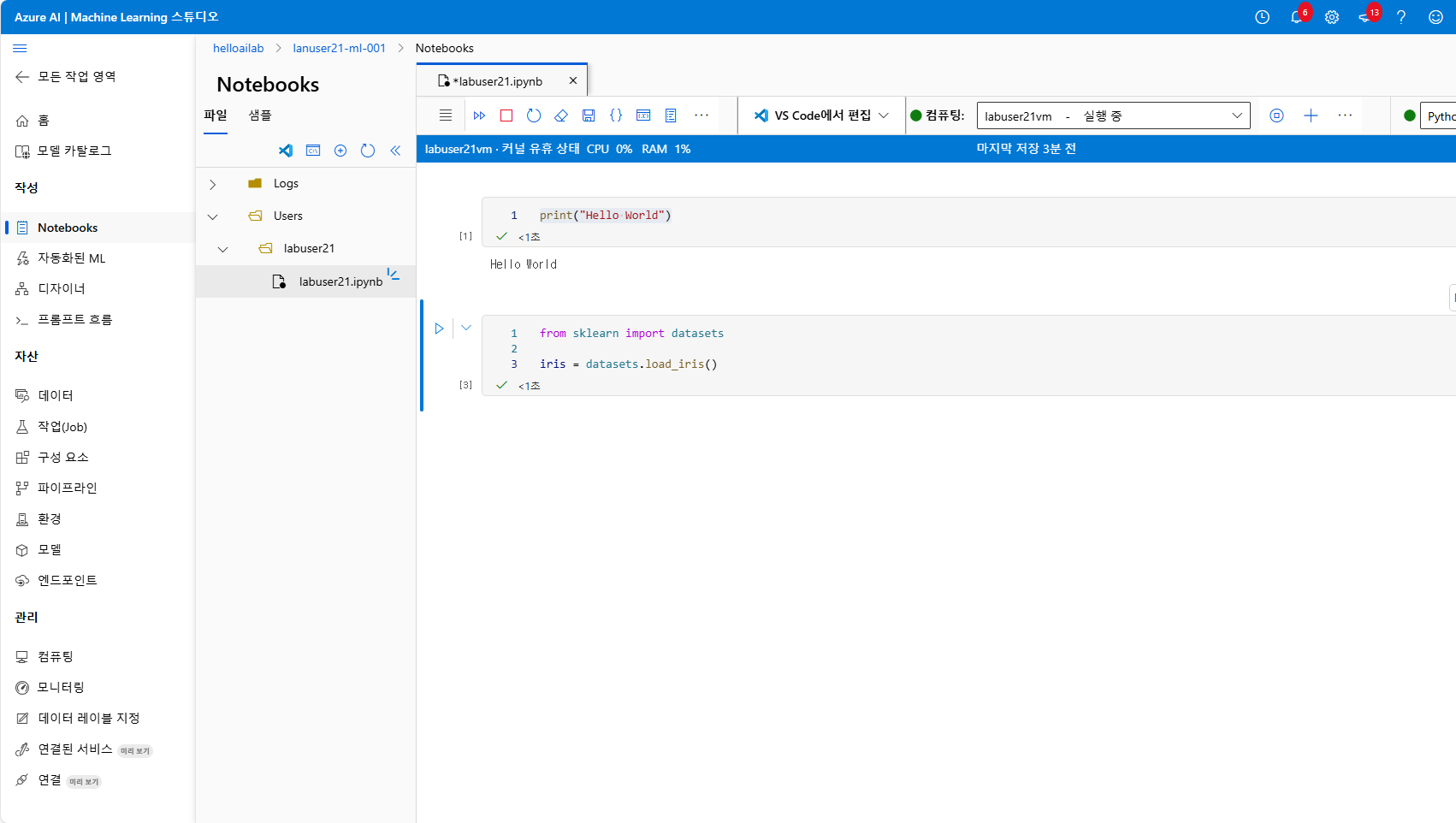
데이터를 불러왔으면
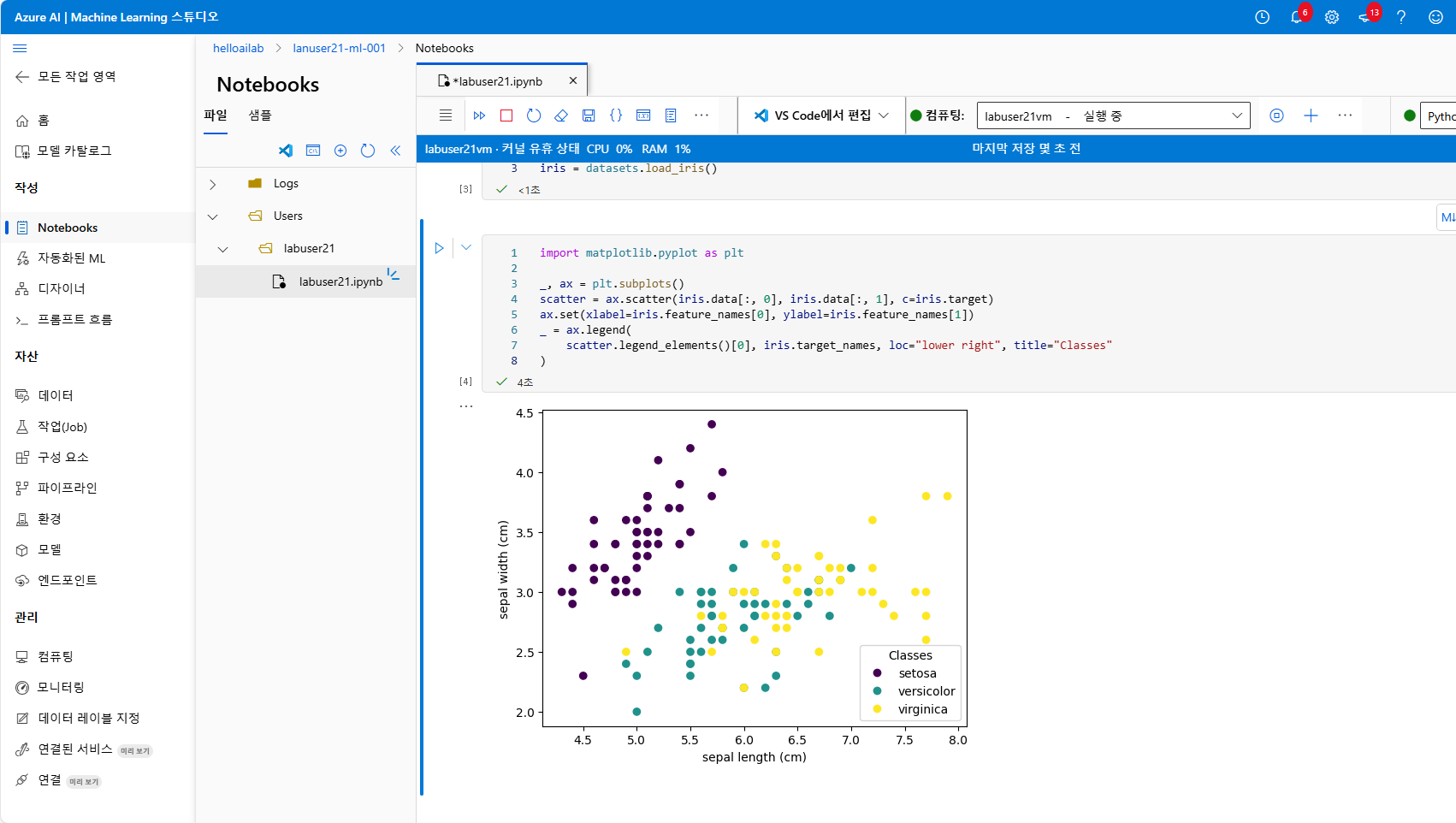
이제 꽃받침(sepal)의 길이와 너비를 기준으로 시각화를 해보겠습니다.
matplotlib을 활용해 산점도(Scatter Plot)를 그리는 방식입니다.
import matplotlib.pyplot as plt
_, ax = plt.subplots()
scatter = ax.scatter(iris.data[:, 0], iris.data[:, 1], c=iris.target)
ax.set(xlabel=iris.feature_names[0], ylabel=iris.feature_names[1])
_ = ax.legend(
scatter.legend_elements()[0],
iris.target_names,
loc="lower right",
title="Classes"
)코드를 실행하면 아래와 같이 결과가 출력됩니다.
각 점은 하나의 꽃을 의미
색깔은 품종을 구분
X축은 꽃받침의 길이, Y축은 꽃받침의 너비를 나타내고
색깔별로 군집이 어느 정도 나뉘는 것을 시각적으로 확인할 수 있습니다.
그러나 아쉽게도
앞서 본 시각화는 2개의 특성만 사용했기 때문에 전체 데이터의 구조를 충분히 보여주지는 못하는 듯합니다
그래서 이제는 4개의 특성을 모두 고려해서 PCA(주성분 분석)를 적용하고
3차원 공간에서 시각화해 보겠습니다.
import mpl_toolkits.mplot3d
from sklearn.decomposition import PCA
import matplotlib.pyplot as plt
# PCA 적용하는 것
fig = plt.figure(figsize=(8, 6))
ax = fig.add_subplot(111, projection="3d", elev=150, azim=110)
X_reduced = PCA(n_components=3).fit_transform(iris.data)
scatter = ax.scatter(
X_reduced[:, 0], X_reduced[:, 1], X_reduced[:, 2],
c=iris.target
)
# 축들 설정하는 것
ax.set_title("First three PCA dimensions")
ax.set_xlabel("1st Eigenvector")
ax.set_ylabel("2nd Eigenvector")
ax.set_zlabel("3rd Eigenvector")
plt.show()
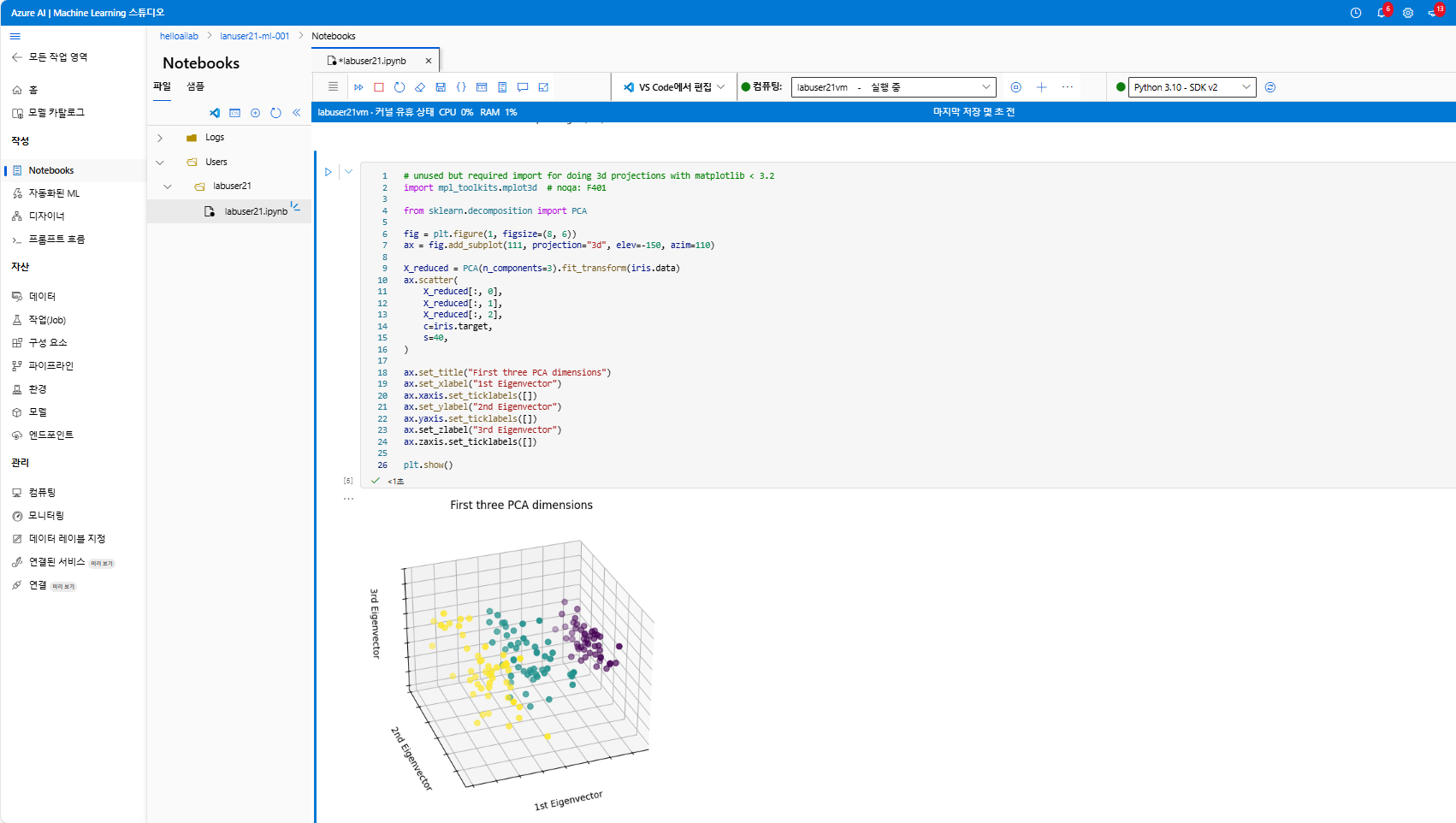
색깔로 표시된 각 품종(setosa, versicolor, virginica)이 그룹을 이쁘게 만든 모습을 확인할 수 있습니다.
Azure Machine Learning Studio에서 제공하는 Notebook 환경을 활용해 Iris 데이터셋을 불러오고,
간단한 시각화부터 PCA 기반 차원 축소까지 진행해 봤습니다.
추후에는.... 아마 PCA 결과를 바탕으로 실제 분류 모델을 학습도 시켜볼까 하는 생각입니다. Azure ML 포스팅할 것들이 많습니다
참고자료
MLflow를 사용하여 Jupyter Notebook에서 모델 학습 추적 - Training | Microsoft Learn
MLflow를 사용하여 Jupyter Notebook에서 모델 학습 추적 - Training
Notebook에서 실험할 때 모델 추적에 MLflow를 사용하는 방법을 알아봅니다.
learn.microsoft.com
load_iris — scikit-learn 1.7.0 documentation
load_iris
Gallery examples: Plot classification probability Plot Hierarchical Clustering Dendrogram Concatenating multiple feature extraction methods Incremental PCA Principal Component Analysis (PCA) on Iri...
scikit-learn.org
Using Matplotlib — Matplotlib 3.10.3 documentation
Using Matplotlib — Matplotlib 3.10.3 documentation
matplotlib.org
'Azure > Azure AI & Machine Learning' 카테고리의 다른 글
| Azure AI - Custom Vision 음식 구분하기 (0) | 2025.10.14 |
|---|---|
| Azure Machine Learning - AutoML로 타이타닉 생존자 예측하기 (0) | 2025.07.04 |
| Azure Machine Learning – Azure ML Designer란? 2편 (0) | 2025.06.30 |
| Azure Machine Learning – Azure ML Designer란? 1편 (0) | 2025.06.29 |
| Azure Machine Learning이란? (0) | 2025.06.29 |