Azure Machine Learning - 고객이탈률(Churns) 모델 만들기
1. 개요
Churns라는 데이터셋이 있습니다.
번역기로 찾아보니 고객 이탈이라는 뜻이라고 하는데요 (그냥 Customer Leave 라 하면 안되는지...)
이번에는 Churns라는 데이터셋으로 Machine Learning 모델을 만들어보겠습니다.
2. 구성 요소
이전에 진행했던 타이타닉 데이터(Titanic Data) 때와 똑같습니다.
Azure ML – Azure ML Designer란? 1편
Azure ML – Azure ML Designer란? 1편
1. 개요:이전 포스팅에서 Azure ML데 대한 기본을 간단하게 알아봤습니다.구성 요소 중 하나인 Azure Machine Learning Designer는개발 지식 없이도 머신러닝 모델을 설게하고 학습할 수 있도록 해주는 친구
ww0610.tistory.com
다만 데이터셋은 요걸로 진행하겠습니다.
이런 데이터셋들은 어떤 분들이 만드시는 걸까요? 문득 궁금해집니다...
GitHub - rohit-chandra/Customer_Churn_Analysis: Customer churn prediction for telecom dataset
GitHub - rohit-chandra/Customer_Churn_Analysis: Customer churn prediction for telecom dataset
Customer churn prediction for telecom dataset. Contribute to rohit-chandra/Customer_Churn_Analysis development by creating an account on GitHub.
github.com
3. 진행 과정
Azure Machine Learning 리소스 생성
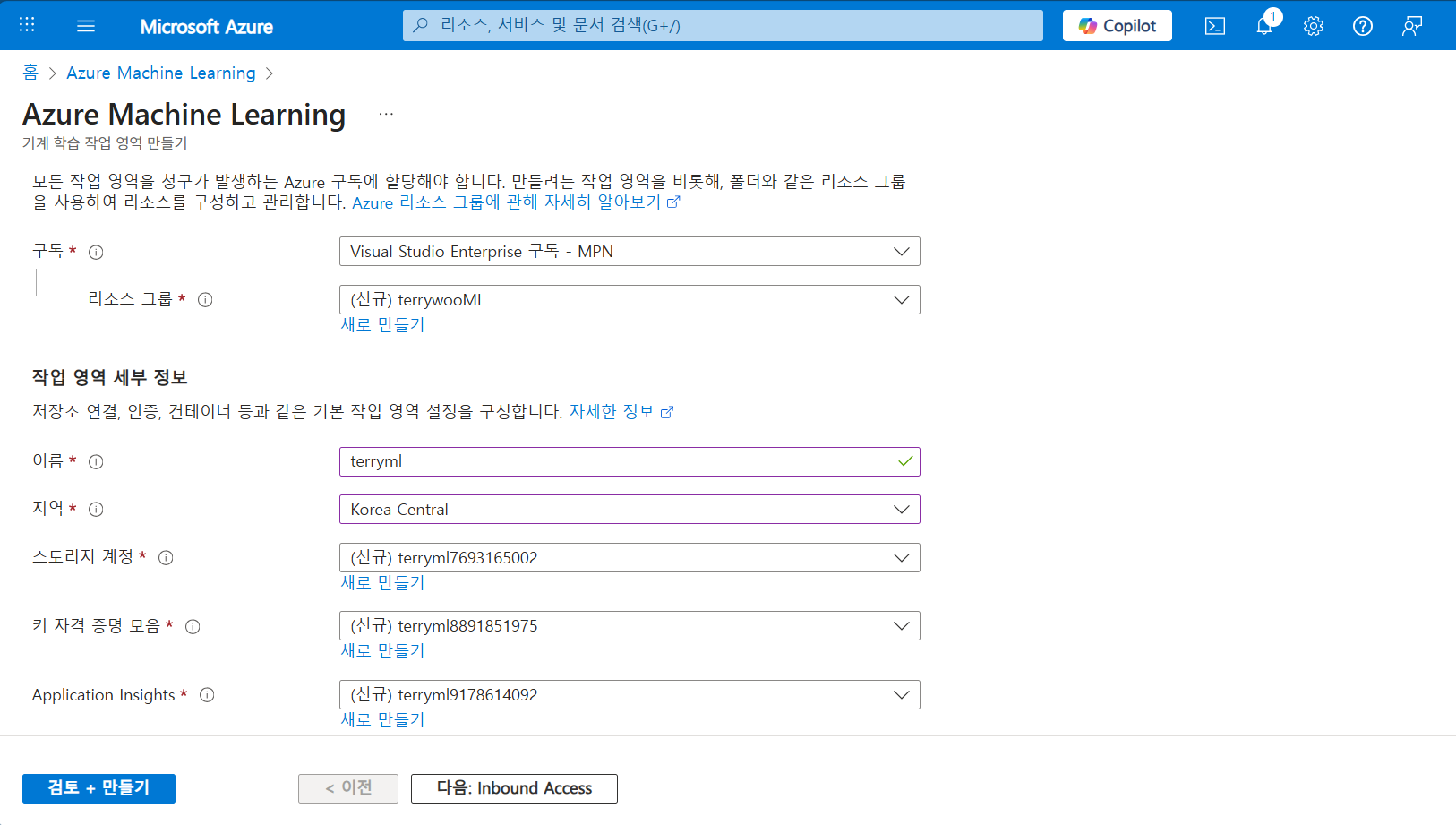
리소스를 먼저 생성해 줍니다.

적절하게 리소스 그룹과 이름, 지역등을 설정해 줍니다.

영어 이름 Terry는 아직도 좀 어색합니다.
만약 배포에 실패했다면 리전을 변경하여 진행하는 걸 추천합니다.

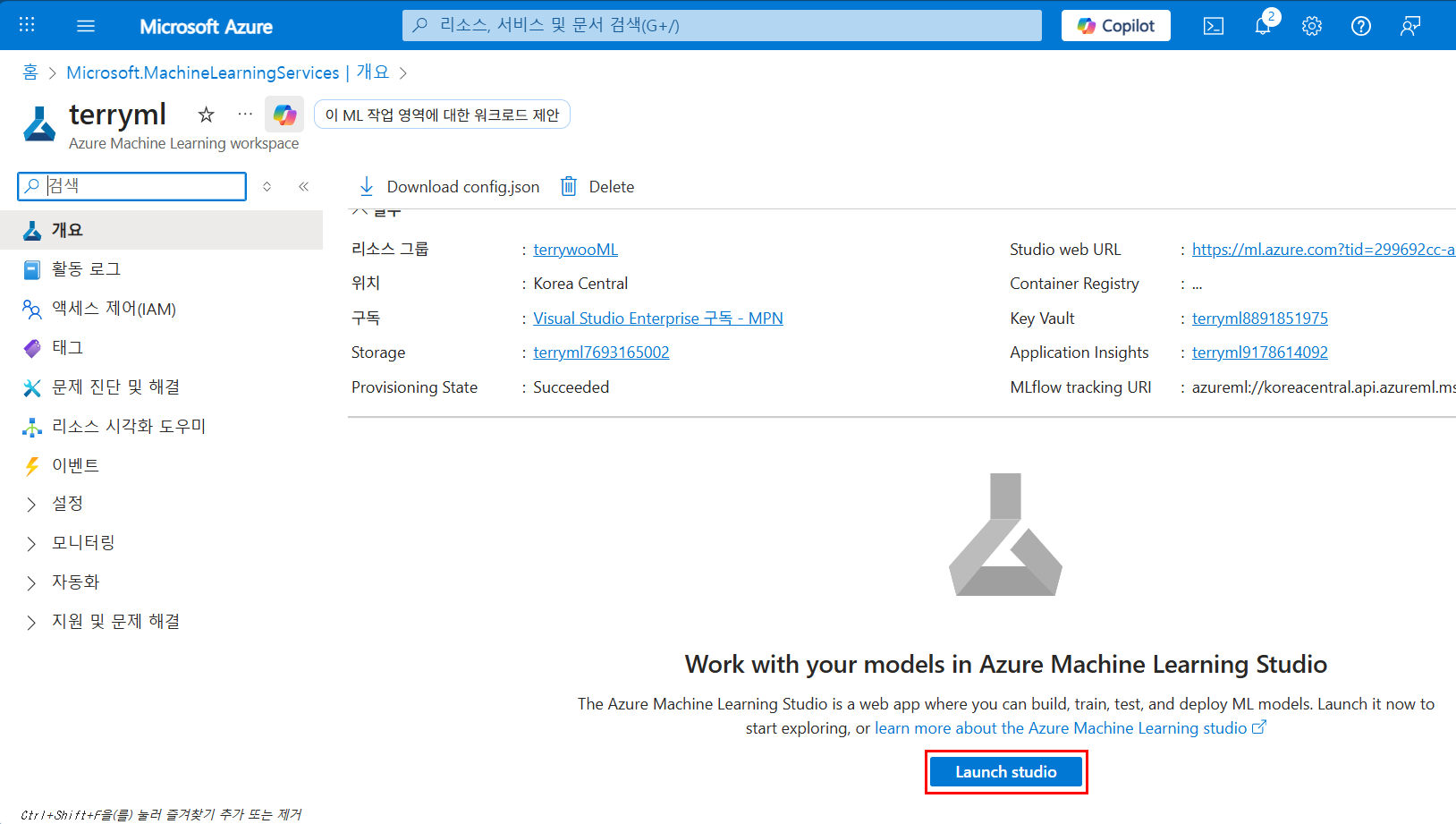
데이터셋 업로드 및 등록
Azure ML Studio가 열렸으면, 작업 영역에 들어갑니다.
해당하는 작업 영역에서는 디자이너를 열어줍니다
이전에 진행했던 글과 비교했을 때 UI가... 조금은 바뀐 것 같습니다.

Azure Machine Learning Studio에서 Designer 새 파이프라인을 만드는 초기 화면입니다.
클래식 미리 빌드 방식에서는 기존에 제공되는 구성 요소들을 바로 끌어다 사용할 수 있으며,
‘+’ 영역을 클릭하면 데이터 입력이나 Split, Train Model 같은 컴포넌트를 바로 배치할 수 있습니다.
이번 실습에서는 이 공간에 Churn 예측을 위한 기본 구성 요소들을 순서대로 배치해 파이프라인을 만들어갈 예정...입니다!

+를 눌러 먼저 모델 학습에 사용할 데이터셋을 추가해 주도록 하겠습니다.
Churns라는 뜻은 마구 휘젓다 혹은 이탈하다는 뜻이랍니다.

Designer에서 사용할 데이터 자산을 만들기 위해 원본을 선택하는 화면입니다.
이번 실습에서는 별도로 준비한 Churns.csv 파일을 직접 업로드해야 하므로
여러 옵션 중에서 ‘로컬 파일에서’ 항목을 선택했습니다.

데이터 자산을 업로드할 때, 파일이 저장될 데이터 저장소(Data Store)를 선택하는 단계인데요
Azure ML 워크스페이스에는 기본적으로 workspaceblobstore와 workspaceartifactstore 두 가지가 생성됩니다.
별도의 설정 없이 기본 Blob Storage를 선택하고 ‘다음’을 눌러 업로드 단계로 진행해 줍니다.

chuns_final을 클릭하여 업로드해줍니다.


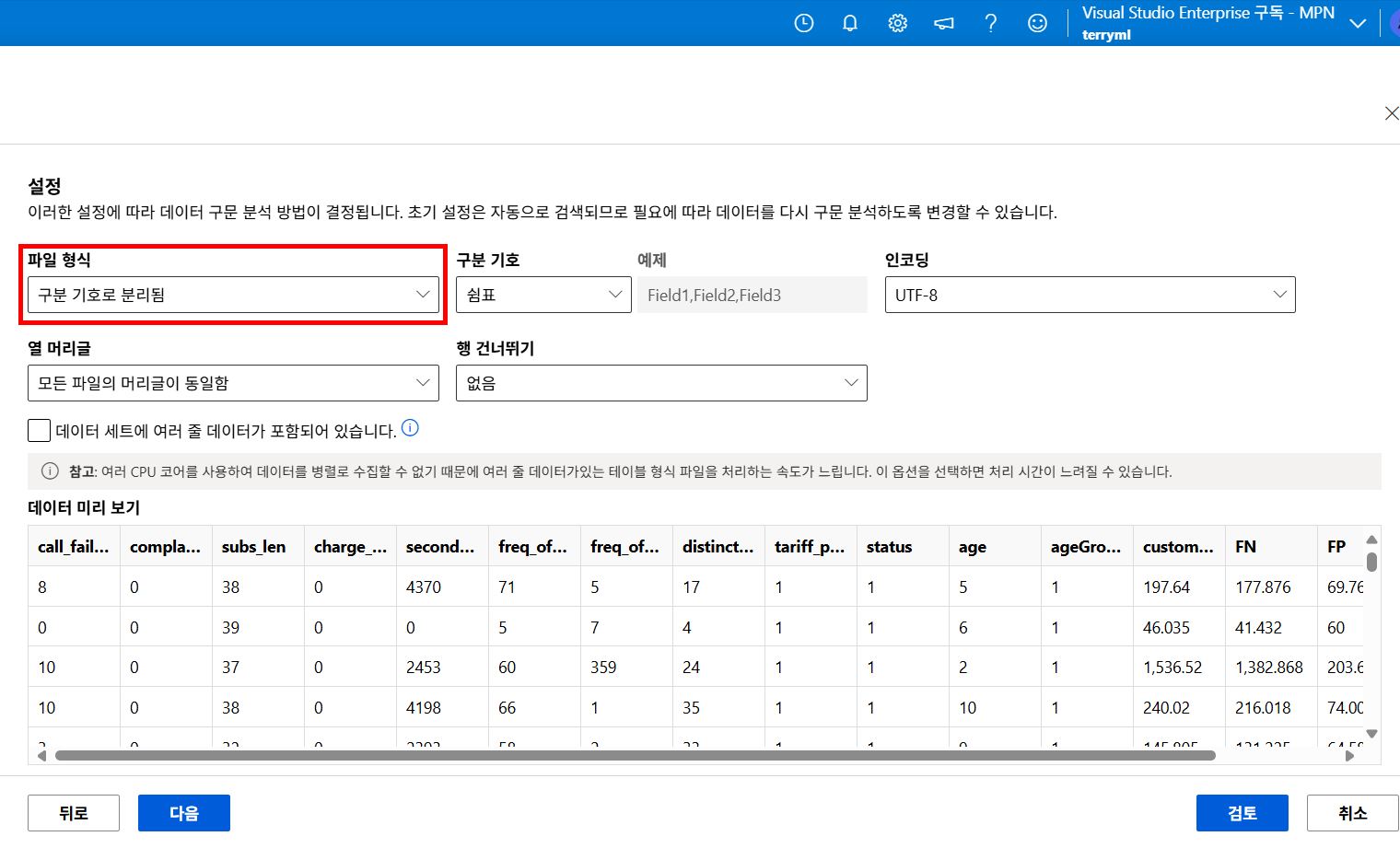
CSV 파일을 업로드하면 Azure ML이 자동으로 구분자와 인코딩을 분석하지만,
간혹 콤마가 아닌 다른 구분자를 사용하는 파일도 있기 때문에
파일 형식과 구분 기호를 명확하게 확인하는 단계가 중요합니다..!
이번 Churns.csv는 일반적인 쉼표 구분 데이터이므로
파일 형식을 ‘구분 기호로 분리됨’, 구분 기호를 ‘쉼표’로 설정한 뒤
아래의 미리 보기 영역에서 칼럼이 정상적으로 분리되었는지 확인해 주는 과정이 필요하겠습니다.
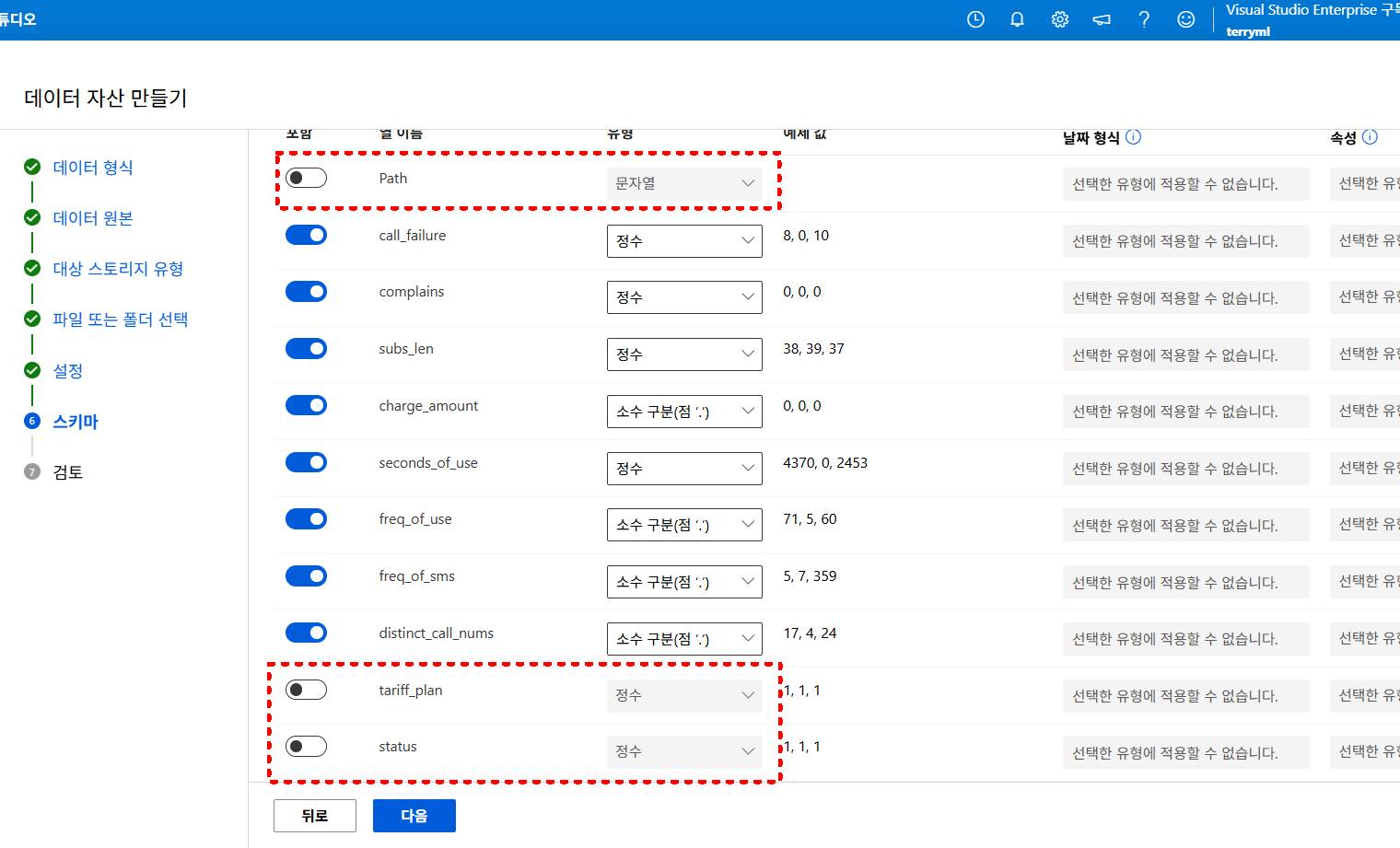
데이터 자산 생성 단계에서 스키마(Schema)를 최종 확인하는 과정입니다.
업로드된 CSV의 모든 칼럼이 자동으로 포함되지만,
분석에 불필요한 칼럼(파일 경로 Path, 패키지 요금제 tariff_plan, 상태 코드 status, 그룹화된 연령대 ageGroup)은
토글을 꺼서 제외해 주도록 합니다.
또한 이번 실습에서 예측해야 하는 타깃 변수인 Churn 칼럼이 부울(Boolean) 타입으로 인식되었는지 반드시 확인해야 합니다.

여기까지가 데이터셋 업로드하는 과정입니다.

Computing Instance 만들기
데이터셋이 업로드되었다면, 엔진 역할을 할 컴퓨팅 인스턴스를 생성해 줍니다 (순서는 상관없긴 합니다.)

혹시 거주하는 집이 서울 자가 아파트라면 GPU를 선택해도 됩니다
저는 월세이므로 CPU로 진행하겠습니다.

인스턴스는 실행하는 동안 과금되므로 몇 분 뒤에 자동으로 종료할 건지 정의할 수 있습니다.
기본적으로 20분으로 설정되어 있으며, 필요에 따라 더 짧게 조정할 수도 있습니다.


파이프라인 구성
이제 대망의 파이프라인 구성입니다.
아까 업로드해두었던 데이터셋을 오른쪽으로 Drag&Drop 해줍니다.

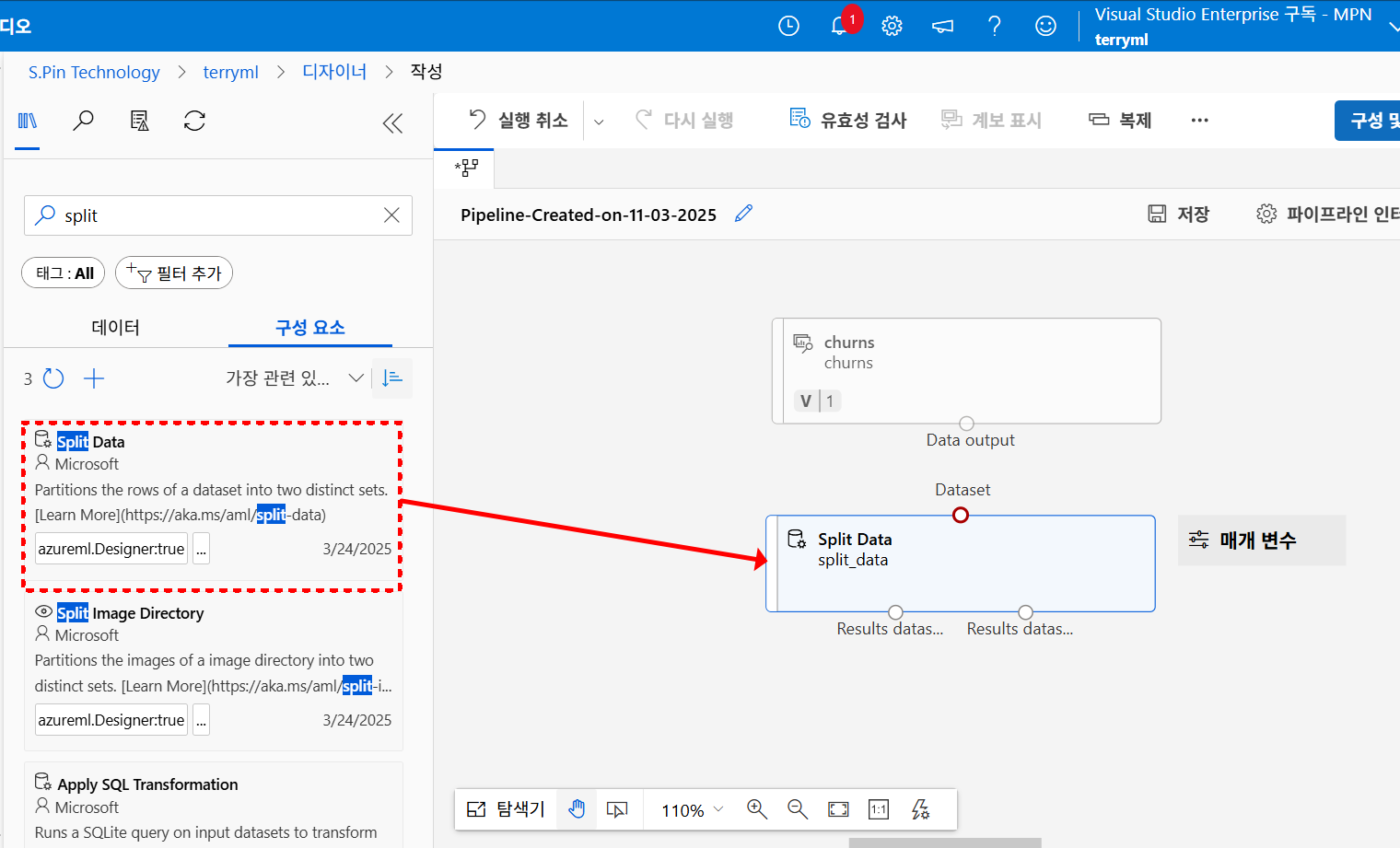
데이터 자산을 불러온 뒤, 첫 번째 단계로 Split Data 컴포넌트를 파이프라인에 배치해 줍니다.
Split Data는 전체 데이터를 훈련용과 테스트용으로 나누는 역할을 하는데요
머신러닝 모델의 성능을 제대로 평가하려면, 학습에 사용한 데이터와 평가에 사용하는 데이터를 구분을 해야 하므로
이 단계는 모든 ML 파이프라인의 필수 과정이라고 볼 수 있습니다.
왼쪽 구성 요소 목록에서 캔버스로 끌어오면 자동으로 딱 Dataset 입력 포트에 연결할 수 있는 형태로 배치됩니다.
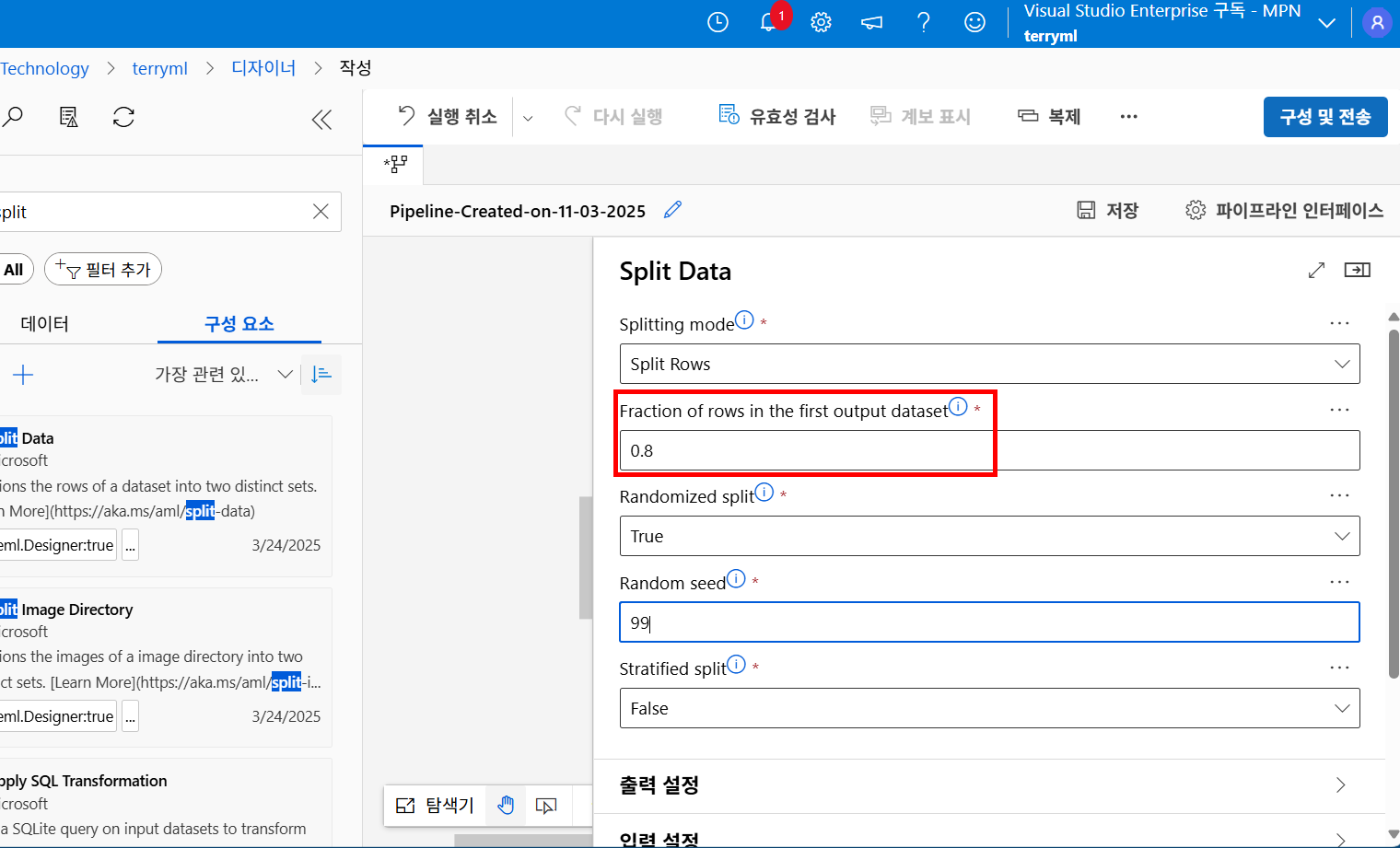
Fraction of rows in the first output dataset은 훈련 데이터에 할당할 비율을 얼마로 할 건지 정의하는 것이고...
이번에는 80%를 학습에 사용하고 20%를 테스트에 사용하도록 설정했습니다.
또한 Randomized split 옵션을 True로 두어 데이터를 무작위로 섞은 뒤 분할하도록 했습니다.
만약 False라면 데이터를 앞에 있는 것부터 잘라서 학습하겠다...라는 것인데!
그렇게 되면 앞단에 좀 데이터가 편향되어 있다거나.. 하는 불상사가 있다면 모델 자체의 신뢰도가 아무래도 떨어지게 됩니다.
또 한편으로 들어보니까 Randomized split False로 해야만 하는 데이터도 있다고는 합니다 흠...
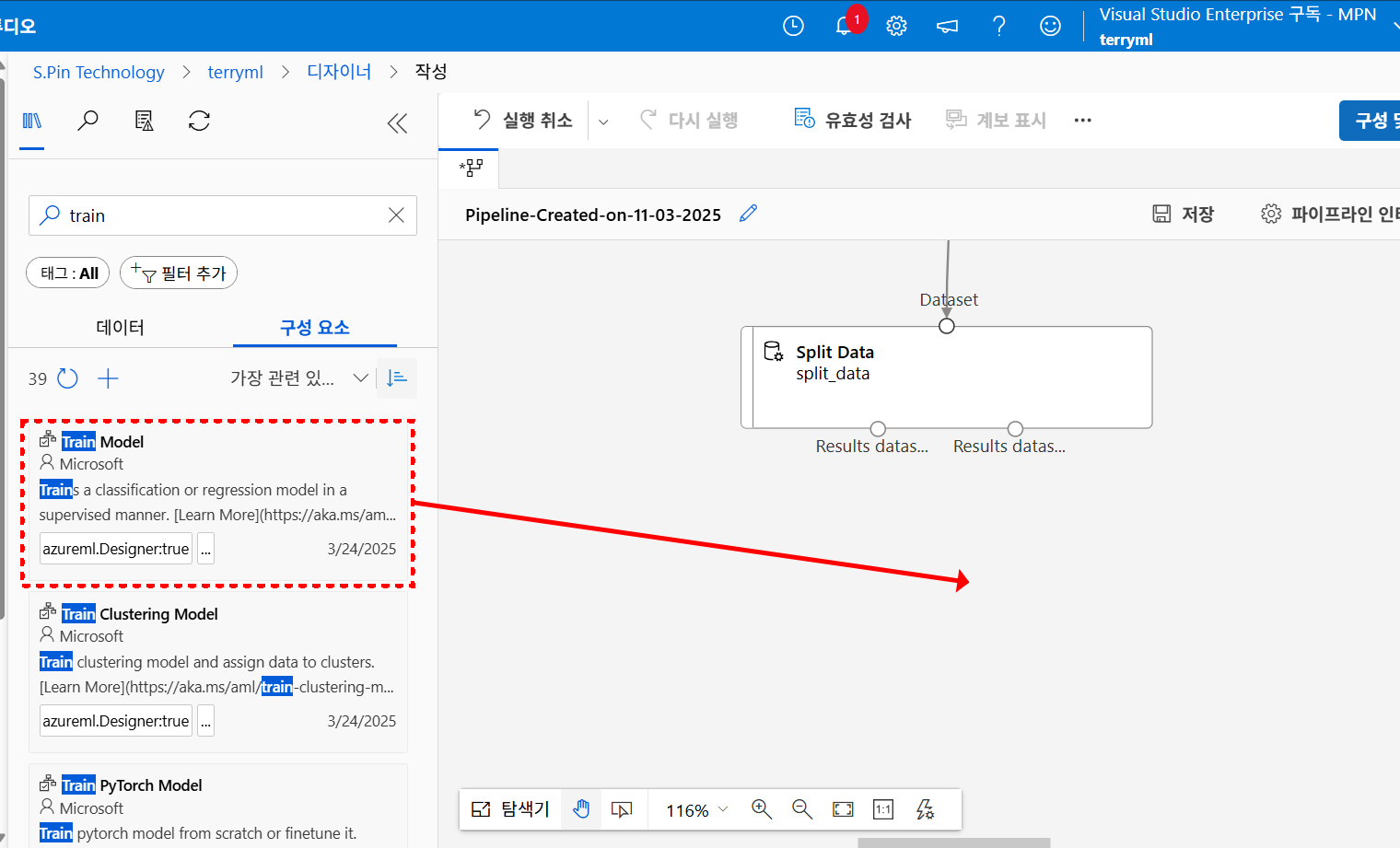
이제 분할된 훈련 데이터를 사용해 모델을 학습시키기 위해 Train Model을 파이프라인에 추가합니다.
Train Model은 이다음 단계에서 선택할 알고리즘으로 모델을 학습하게끔 하는 역할을 합니다.
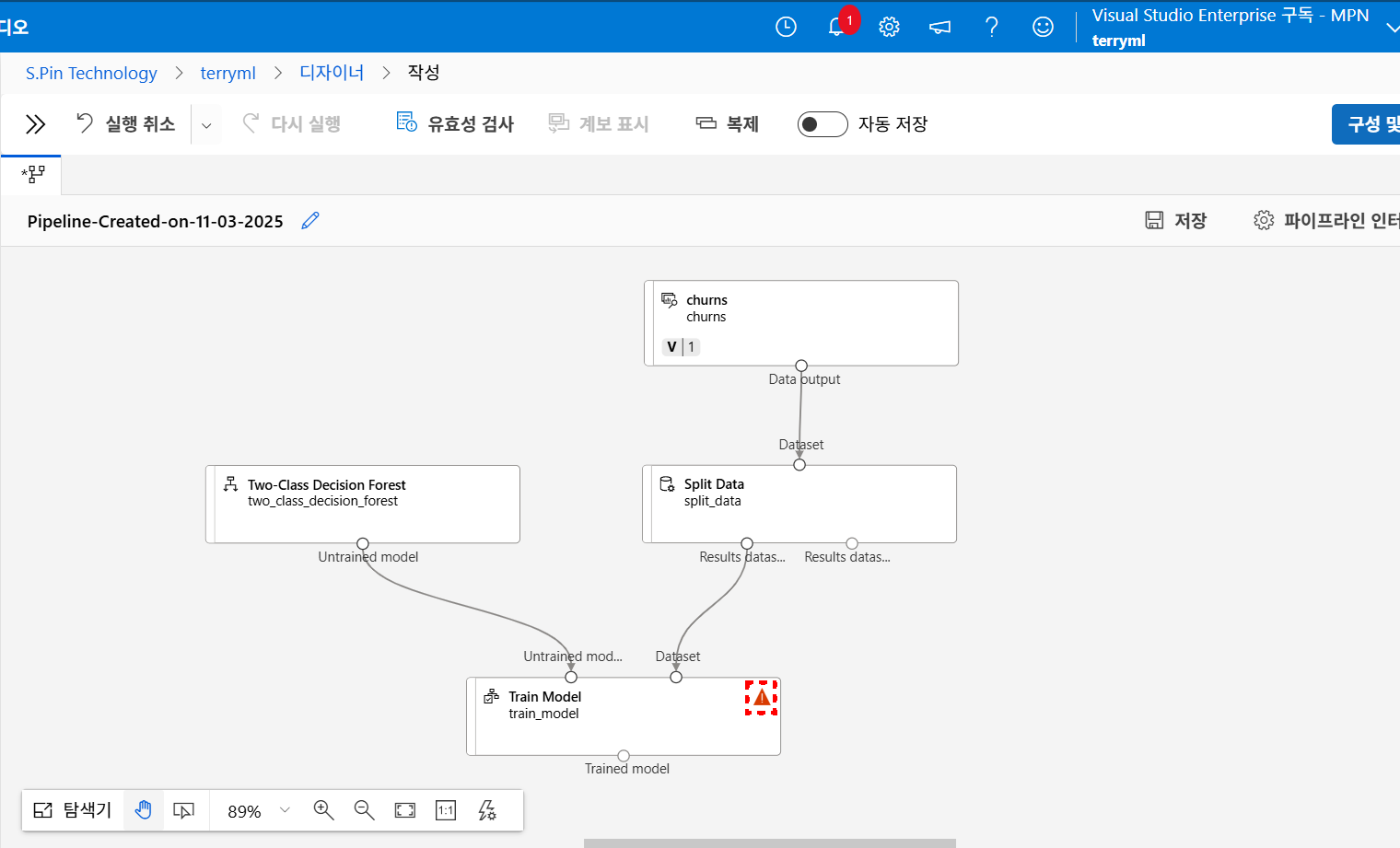
앞서 데이터셋 업로드 과정에서 설정한 것처럼
고객이 이탈할지(Yes) 안 할지(No)를 판단하는 문제이므로
Two-Class Decision Forest 알고리즘을 사용합니다.

그리고 저 기분 나쁜 느낌표 같은 경우는
"아 오케이 Two Class 알고리즘 쓴다는 것 알겠는데 그래서 어떤 기준으로 판단할껴?" 하는 의미입니다.
그러므로...그 기준(Label Column)에 대해 정의를 해줘야 합니다.
Train Model - 열 편집을 클릭한 뒤
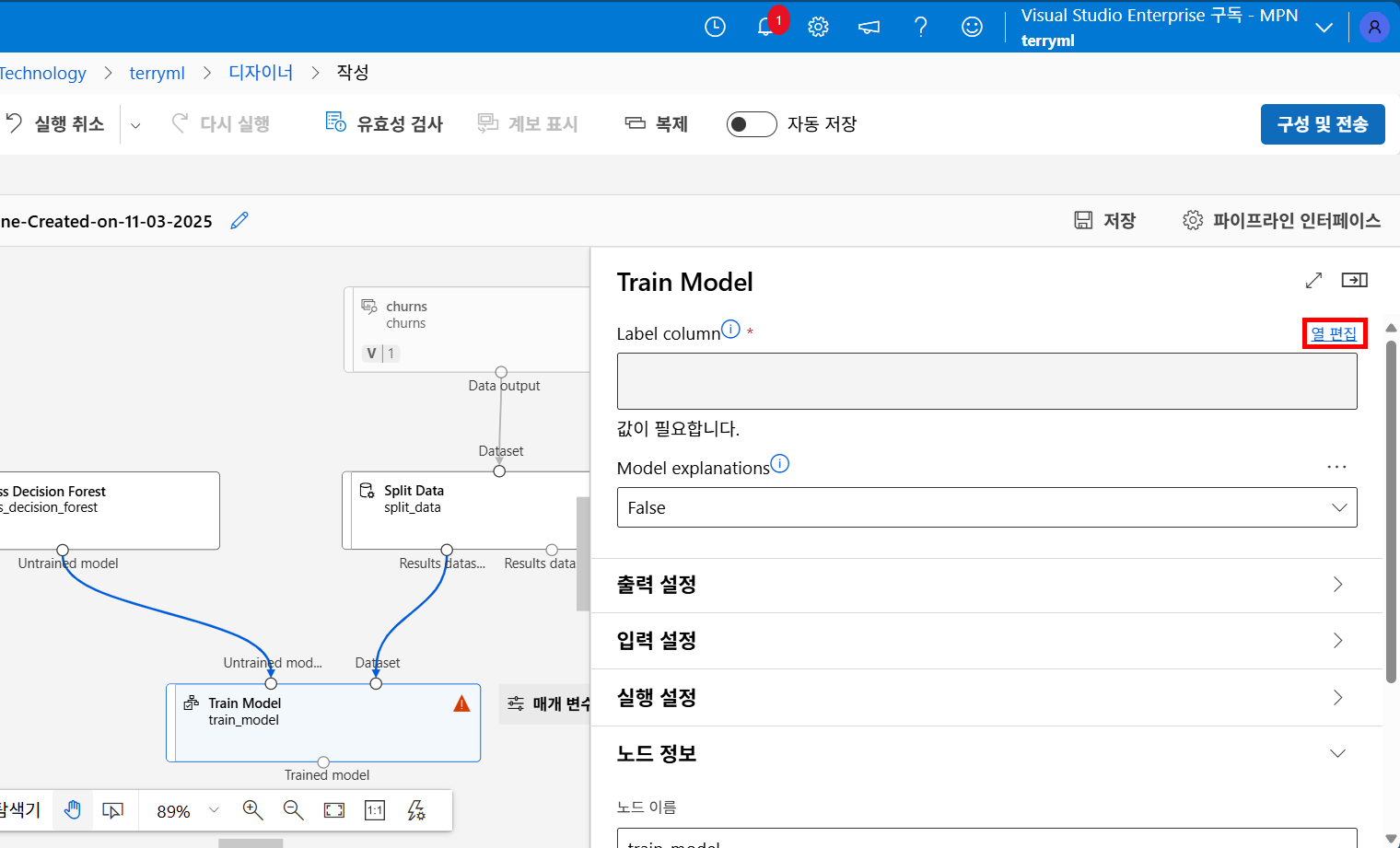
Churn이라는 칼럼을 Label Column으로 등록해 줍니다

짠 기분 나쁜 느낌표가 사라졌습니다!

훈련된 모델 + 테스트 데이터로 에측 결과를 뽑아주는 Score Model을 배치하고

연결해준 뒤...
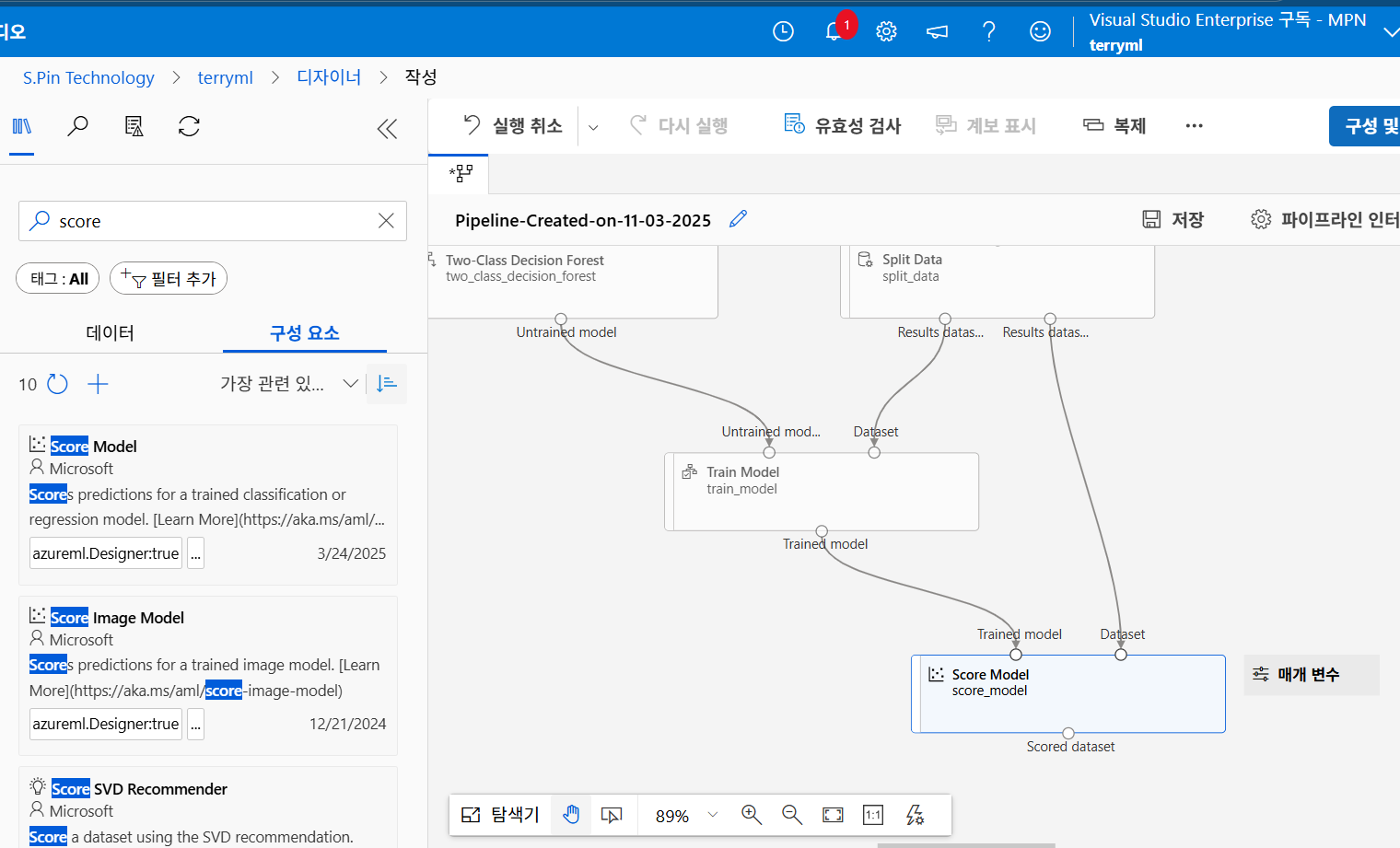
마지막으로 그 모델에 대한 평가 지수를 보여주는 Evaluate Model을 배치해주면

최종 파이프 라인은 완성입니다!

모델 학습 및 평가
파이프라인이 완성되었으면 모델 학습을 진행해야겠죠

아까 만들어준 인스턴스를 선택해준 뒤 실행하면 모델 학습이 진행됩니다.


대략 한 15분 정도 지나면 작업 영역에서 만든 모델에 대해 확인할 수 있는데요.
ROC 곡선 (AUC)은 모델이 얼마나 구분을 잘하냐를 보는 그래프입니다.
그래프가 왼쪽 위로 깊게 휘어져 있으면 잘 만든 모델이며,
정밀도–재현율(PR) 곡선
이건 모델이 정확하게 이탈 고객만 찾아냈는가? (Precision) 놓치지 않고 잘 잡았는가? (Recall) 를 동시에 보는겁니다.
곡선이 전체적으로 높은 위치에 있으면 좋은 모델이 됩니다.

마지막으로 실제 값과 예측 값을 비교해보며 현 모델에 대해 직관적인 평가가 가능합니다.

Machine Learning 이라고 하면 보통 석박사 형님들의 영역인 줄 알았는데
Azure로 인해 저같은 학사 친구들도...? 모델을 만들 수 있게 되었습니다.
AWS로도 같은 기능이 있다면 해보고 싶습니다.
<참고자료>
Azure Machine Learning 설명서 | Microsoft Learn
Azure Machine Learning 설명서
Azure Machine Learning을 사용하여 기계 학습 모델을 학습하고 배포합니다. 빠른 시작을 시작하고, 자습서를 탐색하고, MLOps 모범 사례를 사용하여 ML 수명 주기를 관리합니다.
learn.microsoft.com
'Azure > Azure AI & Machine Learning' 카테고리의 다른 글
| Azure AI - Microsoft Foundry에 Machine Learning + RAG 연동하기 (0) | 2026.01.20 |
|---|---|
| Azure AI - Microsoft Foundry에 RAG 연동하기 (1) | 2025.12.30 |
| Azure AI - Custom Vision 음식 구분하기 (0) | 2025.10.14 |
| Azure Machine Learning - AutoML로 타이타닉 생존자 예측하기 (0) | 2025.07.04 |
| Azure Machine Learning – Notebook으로 IRIS 데이터 시각화 (1) | 2025.07.03 |